
This article appeared originally on Towards Data Science on February 13, 2020. Using Medium, Towards Data Science provides a platform for thousands of people to exchange ideas and to expand understanding of data science.
How AI can solve the notorious data cleaning and prep problems
AI and deep learning have been shining in dealing with unstructured data, from natural language understanding and automatic knowledge base construction to classifying and generating images and videos. Structured data, however, which is trapped in business applications such as product repositories, transaction logs, ERP and CRM systems are being left behind.
Tabular data is still being processed by an older generation of data science techniques, like rule-based systems or decision trees. These methods use handcrafted features, are tedious to maintain, and require lots of manually labelled data. While the recent AI advances allowed mining huge value out of unstructured data, it would be remiss to not pay the same attention to the value of structured data in driving business, revenues, health, security and even governance.
One of the main challenges in structured data, when compared to unstructured data, is the high sensitivity of consuming applications to data quality. We probably can still watch a video with imperfect resolution or identify objects in a slightly garbled image. However, errors in the size, price, and quantity attributes describing the products in a large enterprise or pharmaceutical company can have disastrous outcomes, making data quality an impediment in unleashing the value of structured data assets. While the data management community spent decades trying to address this problem, little progress has been made. This is primarily due to the complexity of the problem, the severe limitation of rule and logic-based systems to handle it, and the very high cost of trying to involve humans in the data cleaning and preparation cycle. Now, it’s clear that only an automatic solution with little to no human interaction is the only viable and scalable solution to this problem.
That is why the problem lends itself to a machine learning solution capable of capturing disparate contexts characterizing enterprise data and learning from large collections of data sets models that can predict the quality of data and even suggest data repairs to boost it. An ML solution for data prep and cleaning will solve long-standing problems for structured data:
- It can combine all signals and contexts including business rules, constraints such as functional dependencies and keys, and the statistical properties of the data;
- It avoids rules explosion to cover edge cases. In many cases managing these rules can be more challenging and more expensive than managing the noisy data they are trying to clean; and finally,
- It can communicate a notion of “confidence” with the provided predictions to be consumed by the right quality-assurance processes in place, or to help judiciously bringing humans in the loop for only the “hard” cases.
However, building an ML solution is not obvious due to the very nature of this data (sparseness, heterogeneity, and rich semantics and domain knowledge). On the positive side, artifacts such as the schema (column names, types, domains, and various integrity constraints) encode important information about the semantics and possible interactions among various data pieces; we can’t have two people live in the same zip code but in two different cities, and the total budget of the project cannot exceed the planned expenses are example constraints that can be explicitly provided. This “structure” makes the value of the data go beyond the statistical properties that can be mined and exploited by machine learning models.
On the challenging side, structured data can be heterogeneous combining information from different domains like text, categorical, numerical, and even image data. It can also be very sparse. Imagine a table with 100 columns, each taking values from domains sizing between 10–1,000 possible values (e.g., manufacturer’s type, size, price, etc) and a couple of million rows describing the products of an enterprise. One can imagine how “empty” that space of possible combinations is, with only a small fraction of the combinations being valid. Without any structure, domain knowledge, constraints, it is extremely hard to learn much about how this data has been generated, or how accurate it is. Hence, we see three main challenges for building a scalable ML solution for cleaning and preparing structured data:
- How should background knowledge be represented as model inputs to help with data sparsity and heterogeneity? How can we communicate, for example, key constraints, functional dependencies, denial constraints, and other complex integrity logic to the ML model to be taken into account while predicting the value in a certain column?
- How to learn from limited (or no) training data and dirty observations? Take for example an “error detection” model, which is supposed to find various errors including typos, missing value, incorrect values, contradicting facts, shifted data etc. Training such a model with very limited available error examples and the presence of these errors in the available data is a challenge to overcome
- How to scale to millions of random variables? A straightforward modelling of the problem as a massive joint distribution of possibilities among all interacting data pieces will simply fail!
We built the inductiv, an AI platform for structured data geared specifically to build models that describe how data was generated, and how it could have been “polluted”. These models are then used in a variety of services such as error detection, error correction predicting missing values, enriching with extra columns, and fusing data pieces. Inductiv builds on the academic open-source project HoloClean (www.holoclean.io), which we started in 2017 as a collaboration between the University of Waterloo, the University of Wisconsin-Madison and Stanford University.
Data Cleaning as an AI problem
HoloClean adopts the well-known noisy channel model to explain how data was generated and how it was “polluted”. The full research paper can be found here. HoloClean then leverages all known domain knowledge (e.g. rules), statistical information in the data, and available trusted sources to build complex data generation and error models. The models are then used to spot errors and suggest the most probable values to replace as a repair.
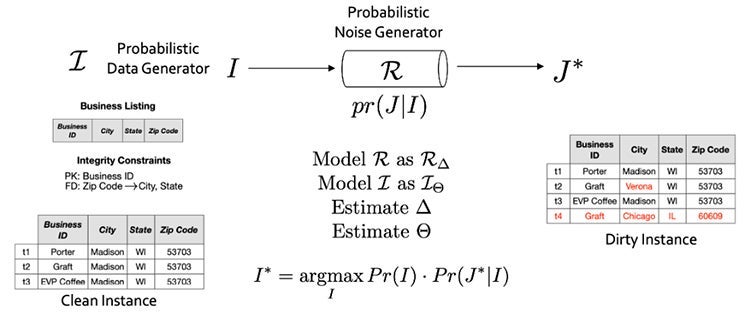
Figure 1: Data is generated clean according to a generative process, we observe the polluted version. Modelling and parameterization these processes allow us to express cleaning as an inference problem
While this model helps by formulating cleaning and detection as inference problems, provisioning scalable solutions with expressive enough models are real challenges.
Building an Error Detection Solution
In our paper on how to detect errors using very few examples, we address some of the previously mentioned challenges:
- Model. The heterogeneity of errors and their side effects makes it challenging to identify the appropriate statistical and integrity properties of the data that should be captured by a model in order to discriminate between erroneous and correct cells. These properties correspond to attribute-level, tuple-level, and dataset-level features that describe the distribution governing a dataset. The model described in Figure 2 learns a representation layer that captures these multi-level features to learn a binary error detection classifier.
- Data Imbalance. Since errors are rare and come in different types, ML algorithms tend to produce unsatisfactory classifiers when faced with imbalanced datasets. The features of the minority class are treated as noise and are often ignored. Thus, there is a high probability of misclassification of the minority class as compared to the majority class. Part of the proposed model is a “data augmentation” process (Figure 3) that manufactures many “fake” errors according to a learned error generating policy. The policy parameters are learned using a few error examples. While this limited number of examples is not enough to train an error detection classifier, they are enough to learn a distribution of possible errors.
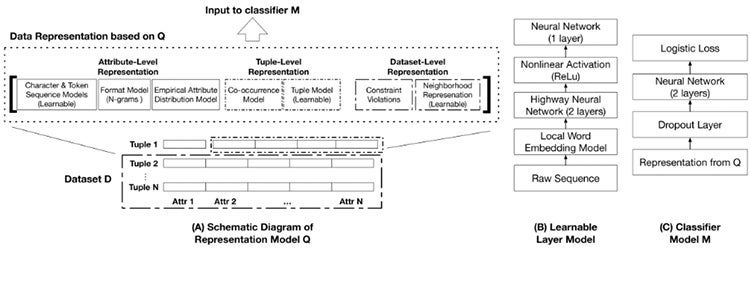
Figure 2: Error detection model with multi-level features
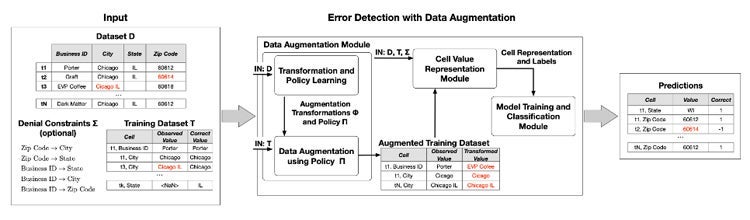
Figure 3: Policies to generate error example are used to solve the training data class imbalance problem
The inductiv Engine: Modern AI for Structured Data
One can quickly realize that data problems such as preparation, cleaning, error detection, and missing value imputation are all applications of a scalable, unified inference engine that is capable of modelling how “structured” data was generated and how errors are introduced. More importantly, for the various reasons we mentioned in this post and the accompanying talk, this core needs to incorporate modern machine learning principles such as:
- Data augmentation and data programming for training data generation
- Learned representation of the various contexts involved in modelling the target column/value, such as learning embedding spaces for the heterogeneous data types
- Self-supervision whenever possible to leverage all the data, using techniques such as reconstructing some the observed data values using other values
- Ways to merge domain knowledge and rules for an extended representation that feeds into expressive models
- System-style optimization for data partitioning and learning local models to allow for both scalable deployments and accommodating data sets with multiple data distributions
The inductiv engine integrates all our previous results in a unified AI core. The predictions produced by this engine can be consumed by a variety of data preparation services. Figure 4 depicts these main components of the core that covers the aforementioned principles, including an attention-based contextual representation mechanism, distributed learning, data slicing, and self-supervision with multi-task learning to deal with different data types (e.g., regression for numerical data and classification for categorical data). In our MLSys 2020 paper, we presented an attention-based learning architecture for missing value imputation in structured data with mixed types (Figure 5).
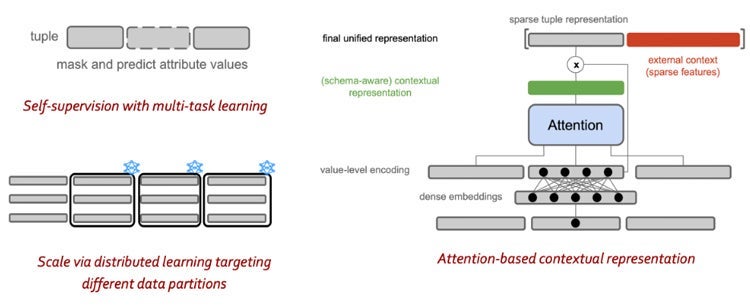
Figure 4: Core Components in the Inductiv Unified Inference Engine
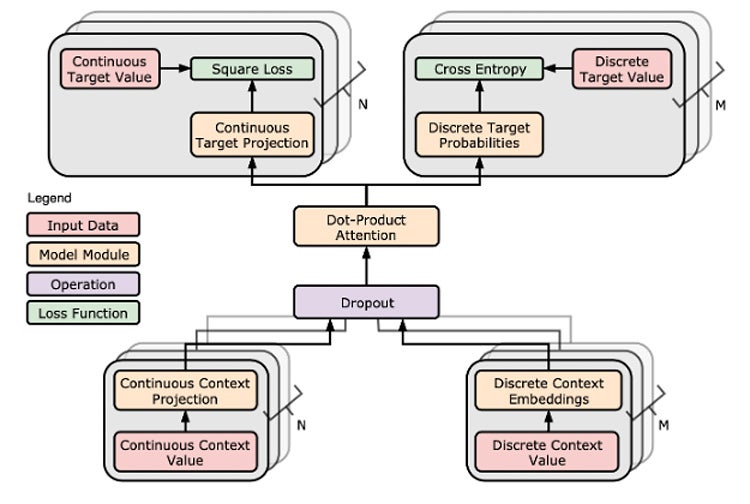
Figure 5: Example Architecture with Attention-based Contextual Representation and Multi-task Learning
Conclusion
A significant portion of today’s important data is structured but it suffers from serious quality problems that compromises its value. Modern AI principles help us treat this notorious quality problem as a unified prediction task, with a new set of challenges around scale, heterogeneity, sparseness, and incorporating known semantics and domain knowledge. We tackle these challenges in building the inductiv engine, the first scalable AI for structured data.