The University of Waterloo and York University have been awarded a grant from the Andrew W. Mellon Foundation to make petabytes of historical internet content accessible to scholars and others interested in researching the recent past.
The grant, valued at $610,625, supports Archives Unleashed, a project that will develop web archive search and data analysis tools to enable scholars and librarians to access, share, and investigate recent history since the early days of the World Wide Web. It is additionally supported by generous in-kind and financial contributions from Start Smart Labs, Compute Canada, York University Libraries and the University of Waterloo’s Faculty of Arts.
“We want to unleash web archive collections by allowing scholars and curators to systematically filter, aggregate, analyze, and visualize content,” says Professor Ian Milligan, the project lead and expert in digital history at the University of Waterloo’s Department of History.
The sheer volume of cultural information generated online over the past 20 years presents exciting opportunities for historians, political scientists, sociologists, and other scholars.
Nick Ruest, digital assets librarian at York University and lead developer on the projects, says it will be a sea change for digital historians. “The systems we are building will dramatically lower the barrier to entry for students, researchers, librarians, and archivists to use web archives in their work,” says Ruest. “It is absolutely critical that these systems exist so that more researchers can truly examine this abundance of web archival data.”
The Internet Archive is a San Francisco non-profit that started in 1996 and currently holds over 30,000 terabytes or 30 petabytes of archival content, a staggering amount of online data that continues to grow exponentially. While public institutions such as university libraries work with the Internet Archive to collect websites of institutional or researcher interest, the current tools for web archive searches are difficult for most people to use and often require prior knowledge of a specific URL, explains Milligan. “Scholars send a request for archival data and get file formats they may not understand. For many, it’s a very slow page-by-page search. So the barriers to entry in this field of digital history are really high.”
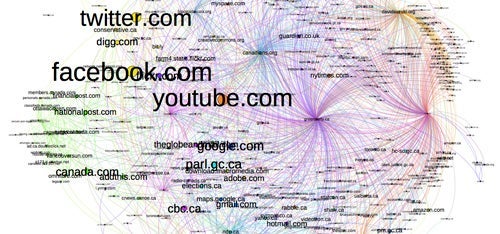
Accessing and analyzing large web archives are currently prohibitive challenges for most researchers in the humanities and social sciences. Milligan and his co-Principal Investigators, Ruest and Jimmy Lin, Professor and Cheriton Chair in Software Systems at the David R. Cheriton School of Computer Science, aim to change this.
The three-year Archives Unleashed project has three major thrusts: First, the project will build a software toolkit that applies modern big data analytics infrastructure to scholarly analysis of web archives. Second, the toolkit will be deployed in a cloud-based environment that will provide a one-stop portal for scholars to ingest their collections and execute a number of analyses with the click of a mouse. Finally, datathons — or hackathons — will build a cohesive and sustainable user community by bringing the core project team members together with librarians, archivists, and other interested researchers.
Explains Professor Lin, “The only way to handle the immense size of typical web archives is to distribute processing tasks over computer clusters. For companies such as Google and Facebook, such infrastructure is taken for granted by legions of data scientists. One of the goals of this project is to bring these capabilities into the hands of historians and other humanities scholars.” The project aims to build on the Apache Spark data processing platform; and, in turn, all tools developed by the project will be released under an open-source licence and shared with the community.
Ultimately, scholarly analyses will feed into visualizations that allow researchers to interactively explore the data — for example, the network of hyperlinks between sites. “Network visualizations will help you see what kind of news outlets a political party tended to link to from their website during the last election,” says Milligan. “Or, every time the Conservatives talked about Justin Trudeau, you can find out what kinds of words and adjectives they used.”
Ruest will focus on a full-stack implementation, building the canonical cloud implementation, ensuring the system is secure, and designing the interface for both data contributors and users.
The project will also seek to expand partnerships with institutions such as universities and government departments. “We really want to enable Canadian partners to take their rich library collections and make them accessible — searchable, with downloadable data and ways to interactively explore the content,” says Milligan.
In the next decades, more historians, librarians, legal researchers, political scientists, sociologists — anyone who wants to work with big data sets — will benefit from this project in being able to unleash their web archives.
This story is jointly issued by the faculties of Arts and Mathematics at the University of Waterloo, and York University.