TWiki> CF Web>InternalProjects>StandardizedAdministrationTools>SATAccountsManagement>SATAccountsRequirements (2023-09-11, DanielAllen)
CF Web>InternalProjects>StandardizedAdministrationTools>SATAccountsManagement>SATAccountsRequirements (2023-09-11, DanielAllen) EditAttach
EditAttach
Standardized Administration Tools (SAT) Accounts Management Requirements
Proposed Requirements
Immediate Implementation
Database
- The database relies on three sources housed within the Odyssey postgres database. See web diagram
 with architecture overview, and SATAccountsDatabase for database details.
with architecture overview, and SATAccountsDatabase for database details. - data from Quest and watiam is campus-wide; our design can accomodate the rest of campus if they want to use this in the future.
- includes data for Grad Students, Faculty, Researchers, Visitors, Staff and Undergraduates - anyone with a watiam account.
- data from Quest and watiam is campus-wide; our design can accomodate the rest of campus if they want to use this in the future.
- updates triggered by timed events following the watiam updates (every 4 hours on the :30; take approximately 7 minutes to complete)
- new schemas cover sponsorship, groups, and other SAT data.
- sponsorship covers accounts, mail aliases, and print quotas currently.
- SAT Accounts API - "wrapper" postgres functions to perform updates.
- Used by CSCF for populating Active Directory. Will eventually be used by MFCF for populating their accounts.
Web UI
- UI will currently offer one administrative access level- eg., for technical staff in CSCF and MFCF.
- use-cases (see-also SATAccountsUserStories)
- add users to "groups" corresponding to course sessions and/or other purposes such as Research Groups. Group membership grants access.
- maintain "sponsors" who are authoritative for budgeting related to groups. Sponsors have optional "billcodes" for each of their sponsored groups.
- UI must intuitively allow management of sponsors without repetitive updates.
Command Line
- replacement for userinfo command
Future Work
Database
- using postgres triggers to kick off LDAP updates would be a useful enhancement so that updates that aren't from watiam will propagate more quickly than up-to-4-hours.
- Grouper integration.
- Could we use the Grouper API to pull Grouper-defined data into our database?
- New types of sponsored resources other than accounts/email aliases/print quota.
- What might we want to automatically set up for different groups of users?...
- Daniel imagines: authorizing physical lab access; students in a course receiving shared git repo access per assigned group; shared LXC container under student.cs; access to any cloud system we can programmatically authorize
- Out of scope to plan for accounts that do not have watiam correspondence. odyssey is driven by the campus user database (with unique internal IDs corresponding to them), and this would introduce another authoritative source (potentially conflicting) that hasn't been implemented or worked through.
Web UI
- user preferences- such as an end-user's preferred/most-used bill codes
- user preferences will allow data filtering, separate from access permissions, so that a user will see the most useful data first
- will be necessary if MFCF is going to see different groups and sponsors than CSCF.
- I've written up how to do this for groups - displaying based on a person's Primary Appointment and that Appointment's default Group.
- an eventual goal is self-service: people have access to the right level of permissions for them to grant resources.
Requirements Gathering notes
- Standardized Administration Tools (SAT) Accounts Management Requirements
- Requirements Gathering notes
- 2019-01-31 - meeting with Adrian Pepper
- 2019-03-22 - meeting with Dave Gawley
- 2019-03-22 - meeting with Adrian Pepper
- 2019-04-02 - meeting with Dave, Adrian, Clayton, Lawrence, and Isaac.
- 2019-04-03 - Lawrence Folland / Adrian Pepper
- 2019-04-16 - Adrian Pepper
- 2019-04-17 - Sean Mason, Lawrence Folland, Isaac Morland, Daniel Allen on Grouper
- 2019-04-21 - Clayton Tucker
- 2019-04-22 - Adrian Pepper
- 2019-05-14 - Lawrence Folland
- 2019-07-30 - Meeting with Dave, Adrian, Robyn, Lawrence, Isaac, Daniel. Regrets from Clayton.
- 2019-07-31 - Dave
- 2019-08-02 - Dave
- 2019-08-08 - Meeting with Dave, Adrian, Clayton, Robyn, Lawrence, Isaac, Daniel.
- 2019-08-15 - Meeting with Lawrence, Isaac, Adrian, Clayton, Robyn, Daniel.
- 2019-09-26 Database Schema: to be discussed between Daniel and Isaac.
- 2019-10-11 and 2019-10-15 Database Schema: discussion between Daniel and Robyn
- 2019-10-17 - Meeting with Dave, Lawrence, Lori, Robyn, Isaac, Adrian, Clayton, Daniel.
- 2019-10-21 Meeting with Caroline Kierstead
- 2019-11-07 - Meeting with Dave, Lori P, Robyn, Lori S, Isaac, Adrian, Anoushka, Daniel.
- 2019-11-29 - Meeting with Dave, Lori, Robyn, Isaac, Adrian, Clayton, Daniel.
- 2019-12-06 - Adrian
- 2019-12-06 - Gang Lu
- 2019-12-12 - Meeting with Dave, Robyn, Lori S., Isaac, Adrian, Clayton, Daniel.
- 2020-01-23 - Meeting with Dave, Isaac, Daniel
- 2020-06-08
- 2020-07-16
- 2020-07-17
- 2020-07-31
- 2020-08-05
- 2020-08-07
- 2020-08-20
- 2020-09-09
- 2020-09-17
- 2020-09-25
- 2020-09-29
- 2020-09-30
- 2020-10-01
- 2020-10-05
- 2020-10-06
- 2020-10-07
- 2020-10-14
- 2020-11-05
- 2020-11-06
- 2020-11-11
- 2020-11-18
- 2020-11-20
- 2020-11-23
- 2020-11-24
- 2020-11-25
- 2020-11-27
- 2020-11-30
- 2020-12-02
- 2020-12-04
- 2020-12-09
- 2020-12-11
- 2020-12-16
- 2020-12-17
- 2021-01-26
- 2021-02-02
- 2021-02-16
- 2021-02-23
- 2021-03-02
- 2021-03-16
- 2021-03-23
- 2021-03-30
- 2021-04-06
- 2021-04-08
- 2021-04-14
- 2021-04-14
- 2021-04-23
- 2021-06-07
- 2021-06-08
- 2021-07-23
- 2021-07-27
- 2021-07-30
- 2021-08-04
- 2021-08-06
- 2021-08-18
- 2021-10-21
- 2022-02-02
- 2022-02-18
- 2022-02-23
- 2022-03-01
- 2022-03-21
- 2022-04-25
- 2022-08-30
- 2022-10-27
- 2022-10-27 Roadmap
- 2022-10-28
- 2022-11-02
- 2022-11-24
- 2022-12-14
- 2022-12-16
- 2023-01-16
- 2023-05-30
- 2023-08-17
2019-01-31 - meeting with Adrian Pepper
Met with Adrian about his perspectives on automated and manual accounts management- Isaac and clayton's tools handle automated cases but do not handle either of the following situations, which cause more work than the automated cases:
- adding people who are auditing a course; (2-5 per term)
- adding people who are not yet in registrar data but intend to take the course (~2 dozen per term)
- Eg. this ticket https://rt.uwaterloo.ca/Ticket/Display.html?id=940127 - includes the 2nd case and those people needed manual sponsoring.
- Eg. this ticket https://rt.uwaterloo.ca/Ticket/Display.html?id=940127
- So we need to consider undergrads as well as grads in this system.
- A current complexity is people not in quest (but are in watiam) who need manual recording in "Research Regions" (currently groups in AD)
- visible from
linux.cs > getent group | grep users_ - 14 groups. list of users come from analysis of accounts_master/data/sponsors/research ...
- visible from
- The importance of recording "sponsorship" - eg., MFCF identified tasks that turn out much easier if there are sponsors
- (I didn't write down any examples)
- sponsors data is organized around classes- including "fake" classes like research groups.
- Q: are sponsors manually set? A: in the current system, sponsor of course accounts is "dean of math"...
- (what kinds of sponsors are manually set?)
- many accounts are by year and we don't actually know if they left before the end... old system threw away what their last situation was?...
- People change their year mid-term sometimes; they might be listed under CS1 and CS2 at the same time.
- what happens on this transition from CS1 to CS2? should they have both resources, or just most recent? Overlap?
- Could we record resources by effective-date/end-date? probably.
- if there are triggers to automatically change the end-dates
- sponsored email aliases
- do we keep doing this?
- put this all into salt?
- some kind of merge; don't want all aliases everywhere;
- who is able to edit? salt is a shift from "administrative data" to "system administrative data" - possibly less easily editable by an end-user than an .aliases file on an archmater.
- noting we run 2 mail servers; probably will keep doing so; raised question of internal-only email.
- email .forward file created by accounts packages - how do we handle this?
- Adrian has written sponsors-range to turn resources files -> start/end dates
- potential ways forward given that we're shutting down 14.04 arch-master.
- no 16.04 arch master. shutting down 14.04 by end of term.
- Adrian says he could set up 18.04 arch master?...
- accounts relies on libraries that would need to be compiled, but they can be on 18.04
- sponsor_resources could be kludged to work on 18.04
- Currently three xhier machines: cs-xh-admin cs-general cs-teaching
2019-03-22 - meeting with Dave Gawley
Met with Dave [update on 31 July 2019]. His summary of related data he wants to access: Course accounts / CS-TEACHING Changing each term, we track:- for each cs course
- co-ordinator IDs
- lecturer IDs
- TA IDs
- BIU (Business Income Units) - (CS Students account-names from odyssey db) - under the new budget model- funding units from the province
- BTU (BIU Teaching Unit) - (non-CS Students account-names from odyssey db) - under the new budget model- funding units defined internal to UW, capacity of a faculty to generate operating grants, according to IAP. data might be from Quest or other UW database
- ta-sponsored student IDs - (add period per calendar +1 or 2 days; auto-expires @ term drop deadline [???])
- lecturer-sponsored student IDs - (add any time, end-of-term expires)
- group (should receive extra resources, such as for project groups)
- resources
- disk quota
- lab room (NOT currently tracked)
- host list (NOT currently tracked)
CS_course_resources
${Course-ID}_account (account-name exists in both CS-GENERAL and CS-TEACHING)
${CS-course-resources}_host (list)
${CS-course-resources}_lab_room (list)
${CS-course-resources}_extra_quota (list)
CS_course_group (list)
${CS-course-group}_manager
${CS-course-group}_members
${CS-course_group}_resources (CS_course_resources)
The CS-Research domain needs this data for each term:
CS_research_group (list)
${CS-research_group}_manager
${CS-research_group}_members
${CS-research_group}_resources (CS_research_resources)
CS_reearch_resources
${CS-research-resources}_host (list)
${CS-research-resources}_lab_room (list)
${CS-research-resources}_extra_quota (list)
Additional to above, add concept of "group" within a course, that gets resources. - Using sub-groups, could give particular people higher disk quota, access to particular machines / labs.
- Q: do we have accounts that don't have uwdir? A: yes:
- course accounts don't;
- role-based accounts such as programming contests don't
- for each "group" (generically defined), we track:
- faculty co-ordinator
- group members
- resources (same as above).
- "group" is currently included in SAT design, with a "coordinator" or responsible person to reference; we need to add:
- resources
- other roles corresponding to TAs and lecturers? Or make these as sub-groups which inherit?
2019-03-22 - meeting with Adrian Pepper
- concerns about composing a person from a set of groups... (I'm not sure why.)
- we get the data from quest; says Isaac says we should be getting the data from OAT. concerned about making that transition smoothly. (Good to know; we can manage that risk).
- Work flow question: "how do we make user account go away?"-
- What do we do about transitional time periods. when someone transfers from CS1 to CS2- we don't want to reap their accounts/files and then create them again.
- The current account system handles "what we want status to be right now" not "do this to this person"
- perhaps handle transitions by ensuring system adds then removes?
- What do we do about transitional time periods. when someone transfers from CS1 to CS2- we don't want to reap their accounts/files and then create them again.
2019-04-02 - meeting with Dave, Adrian, Clayton, Lawrence, and Isaac.
Agenda
- Better understanding of current system for accounts management
- what we need going forward: requirements; nice-to-haves..
- timing for requirements
1. Better understanding of current system for accounts management
- involves manually-maintained text state files - with expiry dates
- automatic additions/removals from certain groups (classes)
- which indicate sponsorship of resources for individuals and groups.
- creates and removes unix accounts directly on linux machines (with a quota)
- user directory created on regional masters - how? to be discovered.
- creates and removes AD-controlled accounts
- handles mailing lists
- sponsors for mailing lists @cs.uwaterloo.ca in CS-GENERAL
- separate: aliases in cscf-specific
- sponsors for mailing lists @cs
- See: flow chart Nov 2018
2. what we need going forward: requirements; nice-to-haves..
- post-processing software is not going away. The new system needs to kick off updates within 5 minutes.
- see photo; tools being developed by Clayton to post-process.
- as of a given day, what are the resources being sponsored?
- as a minimum, we want to update for arbitrary prof's groups.
- nice to have: prof/ta can update their own
- security: using campus authentication as sufficient to create/remove accounts?
- Isaac: exam management will have (modifiable) list of who is in course- we should drive this list of accounts from exam management.
3. timing for requirements
- go-live summer 2019
2019-04-03 - Lawrence Folland / Adrian Pepper
- related to Daniel by Lawrence.
- including "Members" to source sub-files:
/software/accounts-master/data/sponsors/REGISTRAR/csincludes:
======== Class: cs116 Description: CS 116 Load: high Members: <.DATA/cs116 ==== Computing: cs-teaching.cs.private AssignTo: *MEMBERS* ==== Computing: canadenis.student.cs Groups: student_cs cs116_student AssignTo: *MEMBERS* ========
- And
xhier.cs:/software/accounts-master/data/sponsors/REGISTRAR/.DATA/cs116contains 706 lines each in the format of:
userid:nnnnnnnn
- A question of understanding the old system: could postgres inputs generate "resources" file ouput? A: We don't know yet. Daniel to follow up with Adrian/Clayton.
2019-04-16 - Adrian Pepper
- "could postgres inputs generate "resources" file ouput?" A: In theory, I believe yes it could, but with indeterminate, amounts of work. Non-trivial.
- Adrian and I reviewed the white-board data which I transferred to a web diagram
- https://www.lucidchart.com/invitations/accept/5f692330-ce18-4377-a259-d11154d60ca1 - should be visible using "log in using office 365" and @uwaterloo.ca credentials.
- https://www.lucidchart.com/invitations/accept/5f692330-ce18-4377-a259-d11154d60ca1
- Adrian says diagram of new system's "sponsor_computing" needs to also consider:
- ) resource allocations eg quota
- ) account deletion/creation: when student drops one CS course, and adds another, does data from registrar's office accurately reflect this?- Adrian says can't guarantee it'll be within the granularity of the system - eg., might be dropped, then added an hour later - we don't want to have their student accounts go away for an hour.
- existing system will keep their resource allocations
- possibly expire after a few days?
- Retention of away students? co-op; medical leave; ...
- old system: co-ops came back and asked for their accounts to be restored. This involves manual restore from backups.
- existing system will keep their resource allocations
- ) three xh-master machines: xh-admin , general, teaching - do these need recording in the diagram? I don't think so. Just to know these exist.
2019-04-17 - Sean Mason, Lawrence Folland, Isaac Morland, Daniel Allen on Grouper
Lawrence asked Sean to come answer our questions about the status of Grouper ( https://grouper.private.uwaterloo.ca/- Grouper offers many interactions with other campus systems. Might be useful for us to use; or to supply data.
- They have Campus Data -> Quest including:
Academic Level Affiliation -> [4A] -> [ names ] Class Enrollment -> [1191] -> [ARTS] -> [1191.ARTS.130.005.SEM] Faculty Affiliation -> [MAT] -> [names] Plan Affiliation -> [Accounting and Financial Management, Honours, Co-operative Program] [plus 700 more] Program Affiliation -> [Acc & Financial Mgt,H][plus 146 more]
-
- They have Campus Data -> Workday including:
Employee Affiliations -> (Casual Employee, Employee, Faculty, Retiree, Staff, Temporary Employee)
- Includes everyone as recorded in Workday.
- Supervisor data is weird, because workday data has weird workarounds.
- Grouper does NOT have course instructors from Quest, or "course coordinators". odyssey has both- Isaac would be happy to get them this data.
- Similarly, grouper has section membership but not Isaac's concept of "who's in the combined class" - only defined by faculty members in odyssey.
- Is it supported?
- considered production by IST; being used by Science to maintain SPSS license access for students, as well as other units. They will work with us on our needs. Code is freely available and documented
- considered production by IST; being used by Science to maintain SPSS license access for students, as well as other units. They will work with us on our needs. Code is freely available and documented
- How would it be used?
- populates campus AD directly
- AD can have connectors to control unix accounts (see grouper docs)
- AD can have connectors to control unix accounts (see grouper docs
- can consume data from a database view (such as odyssey).
- can read and write grouper data via API
- populates campus AD directly
- What time-lags are there for updates?
- typical 5-minute synch to AD groups (eg., confluence).
- Might be 1-2 hours at high load (once a term they have 100,000 changes at once)
- sailpoint consumes its data and also sees 5-minute lag (with similar 1-2 hour during high load).
2019-04-21 - Clayton Tucker
- Reviewed the web diagram and made clarifications about AD.
2019-04-22 - Adrian Pepper
- Reviewed the web diagram and made further clarifications: no direct path from Quest/watiam sources to the resource files- always via sponsors files.
2019-05-14 - Lawrence Folland
- Proposed development process:
- Clarify the requirements for the new system, including all of the pieces we want to preserve from old system.
- Q: Are we expected to continue sponsored mail aliases and lists? Are we re-implementing "sponsor_resources" code to output these (along with UID/GID registry,
- What is the automated process for students who go on leave or co-op? Adrian says currently students leave, return, find their home-dir files are gone, and ask for them to be restored (from backups- manually).
- Q from Lawrence: will we/can we have a replacement for the "userinfo" command? command line or gui?
- would Adrian require "userinfo" for his tasks?
- are there other such command line tools we need to make work?
- Determine data models that will make this possible; and how existing systems will interact with the data models to: a) automate what we need and b) provide manual access to the parts that are not automated.
- Lawrence wonders if data is already flowing into postgres.odyssey as suggested by this diagram from prior meeting
- Implement web interfaces which provide all necessary manual access.
- Clarify the requirements for the new system, including all of the pieces we want to preserve from old system.
2019-07-30 - Meeting with Dave, Adrian, Robyn, Lawrence, Isaac, Daniel. Regrets from Clayton.
Agenda:
- Clarify our understanding of requirements for the new system, including all of the pieces we want to preserve from old system.
- Current status
- Steps moving forward
1. Clarify our understanding of requirements
- Daniel shared the web diagram which reflects his current understanding of data flow and pieces to be implemented. Key starting points for discussion:
- a database,
sponsor_computing, is being populated with all data currently produced by sponsor_resources - Isaac added hooks into sponsor_resources (C code) to output existing data structures to SQL in addition to the flat text files. - this database is used by psql_update to generate LDIF files and populate the new AD, in production since early this year.
- this process relies on sponsor_resources to generate the data, which will be replaced. (With what? DA)
- this database might have all the elements sufficient to kick off the additional tasks Dave says are under development- eg., quota allocation, account creation and removal, UID/GID registry.
- a database,
- Dave reiterated his request for
a database with schemaaccess to data described on 2019-03-22 - updated in https://cs.uwaterloo.ca/cscf/internal/infrastructure/services/Authentication-Authorization/DB-queries.shtml- And a request for comments on these requirements.
- He would like an API for accessing the database, and methods for users to update the database.
- minimally, administrative users in CSCF need to be able to update course and resource memberships.
- ideally, course managers (faculty members? TA's?) can update their own courses to add special cases). Brief discussion about who should be; this is an administrative/Registrar kind of question for followup discussion.
- Isaac proposes that course managers update special cases within the Exam Management System, which is already used by nearly all Math faculty courses. This would be a smallish addition.
- Isaac says that producing the UID/GID registry falls under things he's already thought about and would be very simple to do in SQL.
- Dave says we can stop being responsible for sponsored mail aliases - handing this task over to IST mail services. For followup discussion.
- We might be able to fulfil the term-goal requirements without significantly revamping the database schema done by Isaac and used by Clayton. For followup discussion.
- Adrian raises a concern about data representation of empty classes. Details to follow.
- Some followup discussion I didn't capture, sorry... flying fast and furious.
- Robyn shared these MFCF pages of documentation: http://www.math.uwaterloo.ca/~rblander/mfcf/old_site/resource.shtml and http://www.math.uwaterloo.ca/~rblander/mfcf/old_site/sponsorship.shtml
- and also he shared: On an xhiered accounts master machine - mfcf.math or xhier.cs (?) see these man pages:
How things work:
accounts-master-package(7)
accounts-master(8)
accounts-client(8)
sponsor_accounts(8)
sponsor_resources(8)
How the data are organized:
sponsors(5)
2. Current status
- Infrastructure has a data-path that populates the new AD, as described in early April onward
- Isaac and Clayton have done schema/database work to output all the (uncommented) detail in the sponsors files.
- Today we found that we might not need much schema change to meet the term goal accounts-management requirements, which would be helpful, though we will still discuss deeper changes.
3. Steps moving forward
- This meeting pointed to a number of threads to be discussed; some were opened in email threads, details to follow below.
- Another meeting to be held ASAP.
Followup emails
- Summary: Isaac notes the database in question is transitional; minimally it will need additions when we determine what should be added via web UI.
- Robyn notes Adrian's question about data in context- what if a course has no members for a month? We will probably need to test this.
2019-07-31 - Dave
- Dave clarified that the existing data in the sponsor_computing schema appears to be sufficient to produce the new AD data (not needing additional contextual data)
- The "schema" he described yesterday is the desired end-goal of data he would like to access, perhaps from a database view. This goes further than requirements for deployment for this Fall.
- Most of the additions are already available in OAT/ASUS.
- BIU/BTU (reporting CS vs non-CS students) is required by the School Director to report under the new budget model. This data would be available in ASIS for each student.
- The most time-critical piece as far as he is concerned is the UID/GID registry revamps. He asked if Isaac might be able to have this ready for production within two weeks? (The alternative is deploying new UID/GID for end-of-December).
- I asked Isaac; Isaac thinks this is doable in under two weeks. He will follow up with Dave. A consideration is whether MFCF can also switch-over UIDs at the same time.
2019-08-02 - Dave
- Dave views the replacement for the sponsor_resources process, is a database transformation of the data sources, into the sponsor_computing schema. And that schema is used to run all of the infrastructure processes such as new quota allocation, account generation/removal, etc.
- To be determined by talking with Clayton/Isaac: does Clayton's psql_update rely directly on OAT data, or is it only relying on the sponsor_computing data which was pulled by the old sponsors files? That tells us more about how far along we are, since Dave thinks we're not relying on much of the old sponsor files. From what I've heard, we are.
- 2019-08-06: Clayton says psql_update does read directly from OAT, not just the sponsor data pulled from files. Good!
- In either case, to eliminate sponsor_resources we'd need to identify what are the pieces of sponsorship data (from new sources, such as the Exam Management UI, and a resources-management UI) that can produce a reasonable output.
- Next week I will replace the web diagram with updates.
2019-08-08 - Meeting with Dave, Adrian, Clayton, Robyn, Lawrence, Isaac, Daniel.
Agenda
- Reviewing diagram
- Steps moving forward
- what will we have working by end-of-term?
Diagram
- Daniel shared the web diagram and made updates to make it accurate.
- For future integration: Grouper.
- Could we use the Grouper API to pull Grouper-defined data into an existing schema? (math_computing? _people?)
Steps moving forward
- Replacing 14.04 (regional masters; collecting home directory paths)
- Robyn will look into replacing /u[0-9] with /u
- Replacing long userids with short userids- likely could be done for beginning of Fall
- old long userids die by attrition
- UID/GID registry replacement - NOT for beginning of Fall
- timing isn't for beginning of Fall, because most new accounts were already registered near beginning of term.
- since overall process isn't changing this term, we need to use the new registry with xhier - replace uid registry program
- new account creation: create course resources for previous/current/next term
- instead of running commands at end-of-term, can have updates at any time
- Clayton, Isaac to decide between eg., ( netgroup = CS100, with netgroup_1199 vs. netgroup_YYYYMMDD )
what will we deliver by end-of-term?
- /u[0-9] -> /u
- short userids
- existence of new UID/GID registry - but not being used for new F2019 accounts
- a roadmap for Fall work
2019-08-15 - Meeting with Lawrence, Isaac, Adrian, Clayton, Robyn, Daniel.
Agenda
- Reviewing progress: a) short userids; b) UID/GID registry.
- Work remaining for Spring
- Roadmap for Fall
Reviewing progress: a) short userids; b) UID/GID registry.
a. short userids- accounts creation always will need to consider (old) long userids.
- q: can we mv all long homedirs too short?
- replacing old long homedir to symlink - one-time
- q: have we decided where homedirs go? /u - assuming Dave agrees.
- in 2015 a suggestion was implemented in code for
mkhomesto allow /nethome/ [ 2019-10-16 : rblanders clarifies that nothing else generates these. mkhomes merely recognizes and accepts it the same as it does /u and /uN ]
- in 2015 a suggestion was implemented in code for
- q: can we replace long group names?
- can we store the long data in the schema? don't have to; it's in _watiam schema.
- we're OK with a one-time change of group-names
- we think we have the policy figured out; and TBD who will do it. Isaac is happy to write script to do the symlink creation.
- q: is there any chance a userid ever is reused?
- possibly staff userids get reused
- need to account for merged userids where old userid gets reused
- looking at what tools directly call the uid/gid code, versus uidregistry program. may be simple.
Work remaining for Spring
- Adrian putting expiry dates into registrar data- to have a better picture for data we're seeing
- UID/GID registry: Isaac will be ready to demo UID/GID database, possibly not uidregister code.
- Isaac and Adrian will look at existing code on idregistry.math
- Daniel, Isaac, and Clayton will have another discussion of new schema.
- Answering q of courses with no people in them?...
- if a course (requesting extra resources/quota) has no members, do those extra resources persist?
- existing tables record what are in the resource files - not the final tables.
- we need new tables to record per-course information. Then revise tools to use these.
- q: does sponsor_resources properly handle user-specified odd directories? Isaac can look at code to answer this.
- if a course (requesting extra resources/quota) has no members, do those extra resources persist?
Roadmap for Fall
-
- deferred two weeks when all are back.
2019-09-26 Database Schema: to be discussed between Daniel and Isaac.
- Draft description found in SATAccountsDatabase. Isaac has not had time to discuss; he and Daniel agree that Daniel will proceed with his draft, to be updated as necessary.
2019-10-11 and 2019-10-15 Database Schema: discussion between Daniel and Robyn
- Robyn has helped clear up Daniel's understanding of the existing schema, both for: how some of the fields are used for both CS and MFCF, and what fields are used in MFCF but not CSCF. Details recorded in SATAccountsDatabase (particularly this diff )
2019-10-17 - Meeting with Dave, Lawrence, Lori, Robyn, Isaac, Adrian, Clayton, Daniel.
Agenda
- Reviewing progress: a) short userids (Isaac/Adrian); b) UID/GID registry (Isaac) c) database (Daniel/Isaac)
- Roadmap for Fall
Reviewing progress
a. short userids (Isaac/Adrian);- we handled most of setup of short userids.
- short group names to match - and home directory name matches the short name.
- will be handled by UID/GID registry.
- started schema;
- has conceptualized a new implementation that closely matches what we currently do, with an expectation of adding new stuff later.
- RFC 2307 and extensions- covers AD extensions that Dave says we should include initially.
- Isaac will review these and propose a solution. Daniel to talk to Isaac next week to see if he's started.
- in progress. See SATAccountsDatabase.
- we have UI "wireframe" on https://www.lucidchart.com/invitations/accept/28add83f-8bc8-4093-9205-4aa1a87326d0
- see also /RT#672674
Roadmap for Fall
- we should have a web demo within a few weeks - to cover the user interface, and database as it stands.
- we set up accounts in November; not going to have new system for November.
- Can development proceed before we have the UID/GID registry finished?
- Dave needs new accounts API, plus data (not just API).
- at a cutover-point ldif code needs to switch over to new code.
- Clarification to the accounts process document: UID/GID tables will be part of the accounts schema; they will be generated when data is available, rather than when it's requested for the user to first log in.
- Dave wants this complete by end of February - by 15th for testing.
- would like API and test data by Jan 2.
- Next meeting in two weeks: Daniel to demo UI; and have details for Dave about API (likely JSON).
- will also invite Lori Suess.
2019-10-21 Meeting with Caroline Kierstead
While doing an off-campus project, Daniel was sitting next to Caroline Kierstead and he asked her about about accounts management from her perspective. These kinds of users need to be manually added to the system:- sessional instructors
- grads (TAs or Research Assistants)
- ISA's (co-op students working on the course).
- depends on the course; primarily depends on the instructor.
- ISC's or instructors might be making the additions
- See-also: https://cs.uwaterloo.ca/resources-and-services/instructional-support-group-isg/isg-people for descriptions of roles.
2019-11-07 - Meeting with Dave, Lori P, Robyn, Lori S, Isaac, Adrian, Anoushka, Daniel.
Agenda
- Reviewing UI
- Recording future directions
UI Questions and Feedback
- Q: What happens at group end date, to members of the group?
- They are still in the database, and listed in the UI; the API will report to Dave's code on active groups, not including inactive, so it can remove access when the group becomes inactive.
- Q: Can we delegate authority to change particular data, to a group of admins? Follow up with Dave.
- Yes, the database can support this, though it's not certain the business-logic and UI will have this complete for January.
- And yes we will have a path for upgrading the code that doesn't take down the production system...
- Q: Dave wants multiple sponsors- eg., two advisors, and the second one will remain if the first one is removed.
- A group can only have one sponsor. However, this can be done in effect by having a group for Prof A, and a group for Prof B, both which contain the student; and they have a parent group, which is the one that we depend on for denoting resources.
- Q: by Daniel: Are sponsorships always explicit, or do we sometimes want them inherited from groups?
- Probably sometimes inherited. Will discuss further.
- UI improvement: Groups: instead of +, "add new member"
- UI concern by Lori S: not very straightforward workflow to her.
- How can we support regular workflows? We walked through adding an arriving Faculty Member to a Group; but it's not clear to her where she'd start. We didn't try and walk through a more complicated example, such as giving the arriving Faculty Member proper sponsorships.
- A basic answer to workflows would be a help page with instructions and links to the appropriate page(s). There aren't hints to the order of pages. (There's more than one way to do it).
- A more complete answer would be application "wizards" to walk through common processes. A list of these starting-points could be put on the front page.
- currently Lori trains co-op students to operate the existing system; spends three weeks teaching them, and then they are able to do it in the proper ways. There isn't a written training document.
- Basic improvements to the UI:
- hover text;
- pulldowns and/or validation, not free-field text for text that should be constrained.
Future features
- user preferences- preferred/most-used bill codes, etc.
- to offer a user filter for data, so that user won't see more than they should.
- will be necessary if MFCF is going to see different groups and sponsors than CSCF.
- I've written up how to do this for groups - displaying based on a person's Primary Appointment and that Appointment's default Group.
- For resources and sponsors, do we need to add a field to constrain what group "owns" the records?
- a goal is self-service: people have access to the right level of permissions for them to grant resources.
- see Dave's first question about delegating authority.
Next steps
- Continuing work from last group meeting (see 2019-10-17) by Adrian, Isaac, Daniel
- UI work by Anoushka
- API work by Daniel and Isaac
- testing a more complete UI with a wider range of end-users - Anoushka and Daniel
- interviews to determine who can make the decisions (see 2019-10-21)
2019-11-29 - Meeting with Dave, Lori, Robyn, Isaac, Adrian, Clayton, Daniel.
Agenda
- Reviewing progress: a) UID/GID registry (Isaac) b) short userids (Isaac/Adrian); c) database (Daniel/Isaac) d) API (Daniel/Dave)
- Plan for Fall
- Plan for Spring
Reviewing progress
a. UID/GID registry (Isaac)- Isaac has schema that exactly reproduces UID registry for general.math - normalized
- analysis shows no data has weird incompatibilities
- next step: interface, for lookups; looking at programs that refer to registry, for exactly what needs changing.
- then, can change to use our new numbering scheme under the hood.
- Isaac can concentrate on this after next Friday.
- new UID registry has long. Isaac is looking into the impact of short, when looking at code.
- possibly: when requesting ID by number, return short/long? Nope, we don't do that currently.
- other direction, by name, can accept short/long...
- Adrian notes registry currently returns long. (yes)
- group search for short returns unknown; long returns correct.
- currently there are existing short groups that are ambiguous truncations
- Lori question: do we need separate AD from these databases?... yes. it's not separate; it's subordinate.
- all one data-pool
- Dave question: where are friendly-name, shell, homedir kept? homedir is important to be included in the database
- shell and homedir not centralized, dependent on "realm" or "region"
- at any time do we want LDAP rebuilt from data-pool?
- Clayton and Isaac to discuss.
- where do we store the list of realms/domains?
- our "forest" is in AD, can we put it in our data-pool.
- Anthony Brennan arriving Monday for a 5 month contract; will be available 1 week later, Dave hopes (one higher priority). Max. 2 projects.
- Dave wants to defer API discussion until Anthony's here, so he's on-board.
- API and test data: deadline: by Jan 2.
Plan for Fall
- UID/GID registry completion
- short userids
- database completion (including stored procedures and triggers)
- API complete (including stored procedures)
- UI: hopefully with end-user privileges; possibly with only global administrator privileges
- Interviews with end-users (Anoushka/Daniel)
Plan for Spring
- Dave would like roadmap for how we get from Fall to done.
- end-to-end how create users? - on whiteboard/sticky notes
- written statement already for what data do we need to authorize an account?
- What can we delegate?
- Math: changing plan. needs design; they are not running AD, will be running salt or grouper.
- Math has an accounts request webform.
- with the end-to-end design, get admin check-off in followup.
- [from previous meeting] Dave wants this complete by end of February - by 15th for testing.
- this requires: API and test data by Jan 2.
- needs to build: new quota allocation/account creation and removal; sponsored mail aliases; command-line tools (?); new version of AD tools that uses new database
- Daniel asked Isaac: how can we satisfy Dave's request for "as-needed" updates, rather than on a timed schedule?
- this would require completely revamping the data process from IST.
- they currently provide _quest updates once a day. Isaac is in conversation with them about increasing to 3x/day, which would make a big difference.
- _watiam updates are ?x/day but we don't know a new user is in courses until we get the next morning's _quest update.
- we could know about name changes more quickly.
- Isaac's proposal: our "trigger" is running after the data gets updated each morning. If that frequency updates, we automatically run more frequently.
2019-12-06 - Adrian
Question: is next week's meeting to discuss end-to-end how we currently create users, or how we hope to create users in the new system?- Our motivation is providing Dave with what he needs to produce the latter. We need to have the former, first, and that's not fully documented. So we are starting with discussing the current system end-to-end.
- Adrian says he currently turns Undergrad Operations data into sponsor text files for sessionals (teaching).
- where does this come from? Gang Lu sends him to a twiki page. See: https://rt.uwaterloo.ca/Ticket/Display.html?id=1023665
- https://cs.uwaterloo.ca/twiki/viewauth/CsOps/SessionalHiringArchive#Winter_2020 - text list of (non-normalized) names. Some don't exist in watiam.
- https://cs.uwaterloo.ca/twiki/viewauth/CsOps/SessionalHiring - Gang's work-in-progress scratch pad for the following term.
- he turns Gang's list into sponsors file:
cs-xh-admin:/software/accounts-master/data/sponsors/School/Sessionals-2001
- where does this come from? Gang Lu sends him to a twiki page. See: https://rt.uwaterloo.ca/Ticket/Display.html?id=1023665
- Grad data is turned into sponsor text files for TAs
- via a script developed by Isaac and Adrian which queries grad office tables (
psql -h postgres.odyssey -d odyssey ; set search_path to _instruct, _identity, _quest, public; [...] - produces sponsors file:
cs-xh-admin:/software/accounts-master/data/sponsors/CLASSES/automatic/TA-cs2001
- via a script developed by Isaac and Adrian which queries grad office tables (
- Some sponsorship data is NOT in watIAM, such as role accounts (cs-pwset).
- those are maintained in the "userids" database:
cs-xh-admin:/software/accounts-userids/data
- those are maintained in the "userids" database:
cs-xh-admin:/software/accounts-userids/data# grep cs-pwset Userids
x:cs-pwset:For Web password:2004/Oct/21 - UWdir
- all entries where the second character is ":" are maintained outside of watiam, such as "x:" (the nomenclature is documented in a README; there are many formats).
- If we are going to decide to put them into watiam, we need to implement a process for that.
- Adrian notes: "Compared to a few years ago, the creation in WatIAM of accounts with a uwuserid corresponding to a userid we are currently using (known to be using) has apparently become troublesome and somewhat time-consuming (for IST). E.g. a recent example of userid "isg"... /RT#1019570 /RT#1020383
2019-12-06 - Gang Lu
I called Gang to ask about her interactions with accounts creation.- she emails accounts@cs concerning sessionals and new courses. She updates SessionalHiringArchive to include a list of names and the courses they are teaching. Both (email and twiki) updates are incremental as she receives information.
- Adrian waits until the list is complete to do them as a batch.
- where does her list of sessionals come from? Her group goes through the hiring process, and for the successful hires, that information is passed along to HR. Tracy D is in contact with HR, but often HR doesn't tell us when they have created WatIAM accounts. With the new WatIAM creation process, HR sends the new hire a registration-link, and they complete their information, and then it falls into a black hole as far as she's concerned.
- if they are recent graduates, yes.
- if they are brand new, she knows that they need them (via HR).
- others are grey areas; some have them already because they are alums.
- She first emails accounts@cs, and eventually if needed she reaches out to other CSCFers such as Nick.
- She wishes we could find out when someone's WatIAM accounts are created by HR; rather than Tracy having to bug them for it. She says recently a new hire emailed her a screen-shot as proof that they did have an account (that she didn't know about).
2019-12-12 - Meeting with Dave, Robyn, Lori S., Isaac, Adrian, Clayton, Daniel.
Agenda
- End-to-end walk through: how do we create users?
- MFCF has an accounts-request webform. Is there a written statement for what data does CS need to authorize an account? No.
- Reviewing progress: a) UID/GID registry (Isaac) b) short userids (Isaac/Adrian); c) database (Daniel/Isaac) d) API (Daniel/Dave)
End-to-end walkthrough
Whiteboards filled, with existing system. Daniel to transfer to something we can potentially edit and markup collaboratively. Identified a number of questions to answer.- Can we eliminate reliance on non-watiam "userids" accounts, moving them into watiam?
- We are in agreement we would like to eliminate that database. MFCF doesn't use them any more. Dave suggests we consider designing workarounds (eg., for visiting faculty who want a userid which cannot be a watiam account. He has seen three, over the years.) Daniel says watiam existence is fairly fundamental to our design- this would be a big deal.
- Can we address this ASAP? (Dave?)
- What validation happens from end-to-end; identifying errors that need to be manually fixed? MFCF relies on regular reports of errors. I believe CSCF debugs errors upon running sponsorships. (Adrian?)
- What auditing/fixing do course-accounts need? Adrian cautions that we do a lot of auditing; we don't know if the course-account owners rely on this, or wouldn't care. These are questions for Omar. (Adrian/..Daniel?)
- How do we use "regions"? There are various definitions in use. (discuss as a group)
- Does CSCF need to consider machines that don't use A/D? Dave notes that Lori does not use A/D for accounts on all cluster machines; typically just for the head nodes (due to network fragility). (Dave?)
- in MFCF, what precisely do "Jim's scripts" do? (Robyn to investigate.)
Reviewing Progress
a. UID/GID registry (Isaac)- Isaac demo'd a schema with custom functions; these replicate the current ID registry functions
- next step: looking at programs that refer to registry, including reviewing source-code on capo/(etc?) and talking to Robyn and Adrian. (soon).
- following: depending on the programs that need to continue, either tweaking their source-code and deploying; or replacing.
- then: can change to use our new numbering scheme under the hood.
2020-01-23 - Meeting with Dave, Isaac, Daniel
- To discuss: API and inputs for Dave's tools; timeline.
API
- Dave's initial request for "views" on data
- Isaac proposes postgres access for queries, and stored procedures, which make queries and updates.
- We've established that Clayton's code is essentially doing all of this, already. Isaac thinks we only have minor work to go?
- What does Dave need?
- White board photo
- SAT API will be read by scripts on linux.cscf, kicking off scripts which send data to the new 2019 CS Windows server, which will send data to LXC client-machines on a new Ubuntu 20.04 server (yet to be setup, likely Feb 1-Feb 15). That server will emulate both general.cs and student.cs for testing.
- the LDIFs for the new Windows server will also be compared to the LDIFs of the current LDAP forest, to validate that new = old.
- This part of the diagram is only an overview; further detail/correction is a good idea, but we didn't go into those details in that 1-hour meeting.
- What does CSCF need, other than the AD-generation?
- setting account quotas: will be supplied by SAT/accounts/"groups" - also read via database queries.
- setting email aliases in general.cs and student.cs - under discussion by managers; might not be needed. We will assume we will implement it.
- on the photo the dotted lines are the data path for setting account quotas and email aliases: data from odyssey -> linux.cscf -> lxc containers for testing general.cs and student.cs
- We are NOT setting print quotas, despite that being in the spec. Dave says these are per-machine only.
- Future potential for adding new types of sponsored resources other than disk quota/email aliases/print quota. What do we want to automatically set up for different groups of users?... (Daniel imagines: automatic grouper updates which authorize physical lab access; students in a course receiving shared git repo access per assigned group; shared LXC container under student.cs; access to any cloud system we can programmatically authorize)
- Re-iterated in the meeting: it's currently out of scope to plan for accounts that do not have watiam correspondence. odyssey is driven by the campus user database (with unique internal IDs corresponding to them), and this would introduce another authoritative source (potentially conflicting) that hasn't been implemented or worked through.
- existing process: picking uwdir IDs is handled by watiam onboarding. Dave's example of "CS Director asks for a visiting researcher's account at 7pm": answer is: self-service watiam for the researcher, which gets them as far as an auto-created account, we think. They won't get a corresponding CS account until an authorized SAT user adds them to an appropriate group.
- creating campus-wide email aliases is handled by watiam.
- Dave asked about Lori P's cluster accounts and off-campus users. Not clear how those accounts relate to campus accounts- not clear how odyssey can see.
Triggers
- Two kinds: the timed events for Isaac's watiam updates, and via Postgres.
- timed events for watiam updates: kick off every 4 hours, on the :30. (and take approx. 7 minutes to complete). Isaac can add a shell stanza that kicks off whatever Dave needs.
- We agree we will use this for now. It covers watiam updates, as well as for UI changes which lead to group and quota updates (up to 4 hour lag)
- vs. postgres triggers can kick off stored procedures whenever any data updates.
- they can also send a "notify" event, which is used by an external listener to execute code - https://dzone.com/articles/notify-events-from-postgresql-to-external-listener
- we agree that using postgres triggers to kick off LDAP updates is out of scope for now. But they would be a useful enhancement so updates that aren't watiam updates will propagate more quickly than up-to-4-hours.
- they can also send a "notify" event, which is used by an external listener to execute code - https://dzone.com/articles/notify-events-from-postgresql-to-external-listener
- timed events for watiam updates: kick off every 4 hours, on the :30. (and take approx. 7 minutes to complete). Isaac can add a shell stanza that kicks off whatever Dave needs.
Timeline
- last month we said the following:
- Dave wants this complete by end of February - Feb 15th for testing.
- this requires: API and test data by Jan 2.
- needs to build: new quota allocation/account creation and removal; sponsored mail aliases; command-line tools (?); new version of AD tools that uses new database
- We're behind on having a fully vetted API and test data.
- Isaac and I will work toward having the API and test data in the next few weeks AKA approx Feb 7.
- Dave wants to have his test environment operational for Feb 15.
Followup with Lori P.
- How are we involving MFCF in these discussions? Robyn L. should be kept up-to-date.
- This time, Daniel to do followup with Robyn independently.
- In the future Daniel to inform Robyn about the meeting in advance, as optional-invite.
2020-06-08
Meeting with Isaac, Daniel. Following a lot of work done in ticket /RT#1015583. Agenda: review and revise draft database schema. Sponsor Computing related questions:- If Clayton determines the "region" from sponsor_computing.computing_name it should be a lookup table, not fill-in text.
- What part defines whether a unix group should be created?
- It's definitely not "all SAT Groups become unix groups"
- It's possibly not "all sponsored SAT Groups become unix groups."
- So there might need to be a field in the group definition table
- Isaac points out that group_group is best limited to general group definition, and another table is best used for the specifics of sponsorship (including the above, group sponsorship unix group)
- Which answers an open question, "what should be the default sponsorship for new courses imported by quest?" - they shouldn't have a sponsorship yet; sponsorship details are separate and subsequent.
- Should group sponsorship have a settable expiration extension time? Eg., person should lose access immediately, but files are not deleted for n months. We know this delay is a spec requirement, but where is the time set?
- All else being equal, account expiration and removal parameters belong in the accounts expiration software (Dave's group), not the database.
- Are unix groups addition/removal a different case? I suggest that no, removal can be set by the active-as-of end date, rather than a separate customizable parameter in the database for amount of time.
- Change the group_group table to add a "source" column, possible values:
- Odyssey (automatically imported by script)
- Manual (updated in UI or CLI)
- Computed (this is new; discussed in depth):
- This may come up in some more complex situations, such as "this research group includes that research group minus this subset"
- I can see the usefulness, but I'd be concerned about complexity of managing these. Noting end-users who I heard say Grouper's interface was too cluttered/complicated for our account-management, and I think they might have been confused with defining groups. (Which is a fair enough complaint; they are complicated).
- My schema's proposed hierarchical trees are essentially "parent is union of its children"; but not allowing cyclic graph.
- I suggested we don't add the complexity of computed at this stage, and could be added later when we had a use-case. Hierarchical meets all the identified use-cases.
- the import process will update/add/delete those labeled "Odyssey"
- the UI will show both; but only allow edits on "Manual"
2020-07-16
Meeting with Isaac, Daniel. Following Isaac's work on the schema mostly recorded in /RT#910469 Prep for tomorrow's project meeting. Agenda: finalizing schema; planning for data loading.- implementing hierarchical groups. Agreed: implement "union" now, for hierarchical groups; other kinds, later.
- he will share v1.0 schema later today; including sponsor_automatic but leaving off the sponsor booleans that were still uncertain (nocharge and nosubsidy).
- we can later re-add those fields if needed
- nocharge might be redunant
- if in the future, MFCF needs to record subsidies, we can make specifications that meet their current needs, rather than whatever the needs were when the sponsorship database was originally defined.
- planning for data loading
- Dave will have a VM "accounts.dev.cscf.uwaterloo.ca" ready later today /RT#1080931.
- Isaac will do some work today on 1st-draft queries to load data
- if we don't have 100% coverage of old groups/classes data, we can work with that in upcoming weeks while Isaac is away.
- future work: making account number into a validated field.
- current work: includes idregistry schema. So Clayton can request new idregistry values without an external tool.
2020-07-17
Meeting with Dave, Robyn, Lori P., Isaac, Adrian, Clayton, Daniel.Agenda
- SAT Accounts Project overall progress?
- Status report and next steps
- Timeline
SAT Accounts Project overall progress?
University funding freeze --> no co-op for Daniel this summer --> web UI won't be delivered until Fall.- Summer: will deliver command-line tools for querying and manipulating database
- Summer: will deliver necessary stored procedures and views for technical client needs.
- Fall: will deliver web UI to meet broader technical needs
Status report and next steps
- schema: will be complete as of today.
- data import: a draft will be complete as of today.
- stored procedures: idregistry = done. Other stored procedures for data updates are not done yet, but will follow.
- Isaac is returning on the 28th but will hand over database details to Daniel today.
- Isaac will coordinate administrative database permissions with Daniel; Daniel to set up access for others while Isaac is away.
- Dave requests a read-only account
- Q: will this include MFCF data? Not before end-of-term.
- Robyn notes that Jim has written code that consumes the flat-files that will need re-implementing.
- Daniel and Robyn will discuss and document what MFCF needs. (Adrian says there are differences within the accounts code; Robyn suspects it is a loosening of requirements so that's not an issue for the new database).
- since we have stored procedures for idregistry, any idregistry replacement scripts can be fully implemented now
- Daniel to set a meeting with ? from Dave's group to discuss implementation.
- other front-end (admin user) scripts can be spec'd and v1 written while Isaac is away, for testing and finding missing pieces; and Isaac will provide stored procedures after he's back.
- Qs about queries
- process for updating resources for TAs, tutors, lecturers? will be command-line. Daniel to discuss the current needs, with Adrian.
- Isaac notes that lots of updates are automatic via odyssey; ISAs and tutors aren't automatic yet.
- can we query who has taught a course for the last 5 years? Yes. What courses a student has taken? Yes. Anything in odyssey could be constructed as a query...
- do we handle ambiguous/conflcting information such as:
- "student added as an exception; then Quest updates automatically." - yes.
- "faculty member A requests privileges for a grad student; faculty member B requests other (or overlapping) privileges for the same student" - yes.
- "faculty member A grants machine privileges for all grads in their research group; faculty member B restricts privileges for their personal workstation" - will need looking into; not yet.
- a) could be done with separate regions, though it's not entirely clear how we will support overlapping regions.
- b) current deliverables do not offer subtraction-from-groups, though that is an eventual feature that's within the realm of automatic update.
- process for updating resources for TAs, tutors, lecturers? will be command-line. Daniel to discuss the current needs, with Adrian.
- deployment timeline? Dave suggests betwen 18th and 31st, since courses are done on 17th. Let's say Tuesday Aug 25th. OK!
Timeline
- database: Done July 17 (Isaac/Daniel)
- dev AD forest server: Done < July 17 (Clayton)
- dev AD client server : July 17ish (Dave/Anthony/Clayton)
- data import, enough for Dave's group to proceed with developing tools: ASAP / either today or week of July 20-24 (Daniel)
- queries for Clayton to programatically query database: July 20-25 (Daniel, with Clayton, possibly Anthony)
- stored procedures to update database: start week of July 27 (Isaac)
- maintenance tools to update database: start week of July 20; may depend on stored procedures. Through mid-August. (? Dave's group / Daniel)
- discussion of MFCF database needs: July 20-25 (Robyn/Daniel)
- test that the database is complete: start week of July 20, through mid-August (Clayton / Daniel / Isaac)
- production-ready / flip the switch on the new AD: August 25th at the latest
2020-07-31
Meeting with Isaac, Daniel. Agenda: What is top criticality? What are we blockers on?- process for auto-populating groups from class data
- data import on S2020 accounts so Clayton can do ldif comparisons
- rest of existing data import, for the rest of our requirements
- process for auto-populating groups from class data
- re-deploying test database with more data (currently MIA due to his testing work)
- being clear on the three queries "what users need to exist in the region; what groups need to exist; which users are in which groups"
- possibly followup with Clayton about writing queries.
- process for converting data to populate sponsor_unixgroup and sponsor_login tables
- schedule a group meeting- ideally for Wednesday afternoon, assuming people are available.
- supply stored procedures, including to manually add a person to the database
- confirm with Dave's group that we are supplying the necessary data/stored procedures/views for maintenance tools
- including or excluding imported data for quotas? Depending on import, that may add complexity.
- look at 'userinfo' command and figure out what pieces of data are missing -
- (noting we will NOT be providing a precise replacement; hopefully there aren't maintenance scripts that try and parse userinfo output).
- document what is not auto-importing from old data; as a precursor to discussing fallback procedures:
- can we use the old system to do mail aliases? (this is mostly static data, since we think changes are largely made from include-files)
- more generally if our best efforts at auto-importing data aren't good enough or we haven't given INF enough time to code and debug, is the old system an option for Fall?
2020-08-05
Meeting with Dave, Lori P., Isaac, Clayton, Daniel. Robyn is away today. Adrian is away for part of August. Agenda: Progress report- Daniel has process for converting data to populate sponsor_unixgroup and sponsor_login tables.
- Yet to be implemented in SQL.
- Isaac has set up process for auto-populating groups according to class data;
- re-deployed test database with more data (groups; sponsors; has a sample entry for ? unixgroups ?)
- has done followup with Clayton about sample queries.
- Dave notes that account creation for Fall term may have already happened in the old system- Adrian does it earlier than end-of-term.
- Daniel to work on UI in the Fall, with co-op.
- Dave: wants access to watiam hidden flag. Isaac can add to some view.
- Dave: wants access to section, for Clayton to make netgroups for it. Isaac says he will expose all the groups that odyssey knows about, which will include sections.
- use-case: different resource requirements for different instructors in the course. Another use-case: different resource requirements for undergrads in 440 and grads in 640 (currently in one section. Hmm.)
2020-08-07
Notes from Daniel. Open questions, to discuss with Isaac.- group_depends population: how far are we from being able to record groups-of-groups?
- necessary for recording computing_group memberships
- from ticket: transactions table for auditing changes - pro/con?
- the old system [as represented in postgres] will apparently create a new "class" or computing_group if you assign an individual user resources. Essentially a group of one. How should this work in the new system? Is it the same process under the hood, of an explicit "group" or is there part of the design that accepts user records in lieu of group?
- the import from old data includes a number of 'away' classes, eg., cs2, cs6 ... I assume we already have that data automatically from quest?
- We need to preserve (not deactivate or delete) accounts for students who are away. We will need a clean way to provide this information to Dave's group.
- the import includes course groups, which are a duplicate from Quest. After we've analyzed the patterns, should we drop course groups?
- keep it for historical info? Would likely be a lot of work. * For now let's assume we can drop it; could be a request for later.
- feedback about current need for 9 vs 7 vs ? region names
- reverse-engineer person-to-group in the old system; manually identify exceptions to the known group memberships.
- identified groups with different end-dates for different users: (17 in cs-general, 2 in teaching)
- are there other user exceptions I can find?...
- hopefully not important: resolve: 573 unique class_names, 580 unique (class_name,class_description)
2020-08-20
Meeting between Daniel and Isaac. From open questions above:- group_depends population: how far are we from being able to record groups-of-groups?
- Existing: how to record group dependency as union/difference. To do: populating a list of the dependent groups.
- Isaac will work on this as a priority.
- transactions table for auditing changes?
- Agreed, we'll add a transaction table.
- we want to record why something was done. Do we need a separate column for comments and for RT number? Or just RT?
- Agreed: include both ticket_id column plus comment column. RT tickets are sufficient for CSCF updates- indeed, the web UI can look up the ticket subject. But comment column is necessary for updates by other users who don't use RT.
- the import from old data includes a number of 'away' classes, eg., cs2, cs6 ... I assume we already have that data automatically from quest?
- yes, there will be automated groups for who is in what plan; who is a co-op; so there will be automated groups for cs_away.
- the import includes course groups, which are a duplicate from Quest.
- convert? keep it for historical info? Would likely be a lot of work.
- No; don't bother. Superfluous. So I will skip over importing cs_students into sponsor_unixgroups.
- do we need to relax the constraints, to allow a unixgroup to have different (start,end) dates for different group_groups?
- people are automatically in courses; courses are automatically paired with unix groups. So teaching environmment shouldn't need different dates for different groups.
- Are there legitimate reasons why a single unix_group might have different (start,end) for different group_groups?
- example: research group X is given access to core www_logs for a limited time. Definitely this is different from the access of other users of www_logs.
- Isaac suggests we can resolve this by assigning the research group X a time-limited group_group of www_logs. I think that's OK. I will look into the data further.
2020-09-09
/RT#9104692020-09-17
Webdev checkin: Isaac, Anna, Daniel, Niya- Discussed setup and postgress access.
- Daniel will make Niya a dev postgres account as per Isaac's instructions (from elsewhere...)
- Discussed psycopg2 stored procedures:
callproc(procedure, parameters)
2020-09-25
Webdev checkin Discussed latest version of schema, which Isaac has checked in- Some areas yet to be filled in.
- Isaac will work on the auto-update of computed groups
-
init_perm.sqlincludes the "API" which is functions granted to other roles, including public. This will be expanded. - Daniel noting:
group_member_insert()is idimpotent - inserting a member into a group they are already in will silently succeed. UI will handle if it should have a warning in that case. - Isaac will rename account to billcode
- Isaac to add auto-import so every user in the system automatically has a group
- Isaac to add transaction table
- We'll plan to begin implementing using the new schema soon.
2020-09-29
Meeting with Lori Suess, Robyn, Daniel, Niya, Isaac to discuss accounts/sponsorship workflow and process in MFCF.- Recorded video: https://web.microsoftstream.com/video/a77c9008-1b5b-4e2c-9be9-34c13954c1ae (1h 10m)
- More notes to follow.
- Lori walked through a variety of workflows relating to account management.
- Timing: ideally Lori doesn't want to need to learn this and teach co-ops at a term boundary. Next term (or later!) is fine; they aren't in any time-crunch.
- Daniel to write up notes from this meeting
- Daniel and Niya to discuss UI involvement
- Daniel/Niya/Isaac to discuss any necessary schema additions/changes
- One obvious addition: We were going to remove sponsorship for printing, but Math uses it and will continue to use sponsorship for printing.
- We will need a follow-up meeting for Daniel/Robyn/(Jim?)/Niya to discuss "Jim's Scripts" which operate on comments in files within the sponsorship file tree.
- Initial thoughts: these scripts cover groups and not users. As long as the group names map directly to SAT groups, perhaps they can continue working unchanged.
- We will schedule a follow-up meeting as soon as we have UI samples for Lori, Jim, and other users to look at.
Workflow demo and discussion
* A faculty member, or visitor, or staff member, will visit https://uwaterloo.ca/math-faculty-computing-facility/- This form contains all the information MFCF needs to make accounts.
- requestors will fill in "Printer access: Applied Math printer" or rarely "Printer access: Yes" but Lori prefers "lpr_am"...
- Form results are sent via email to Lori and the co-op, who either handles it or triages who can do it. The requests aren't sent to RT.
- MFCF knows typical defaults for specific groups including nexus.
- They determine where in the sponsor flat-files they should put the addition, such as for faculty / administrative.
- They add the person to the appropriate file used by "Jim's scripts" - to add them to nexus groups. (eg., "am_other" for applied-math printers, access for others who are not staff or faculty.)
- they use nexus groups to replace lp_quota; and increasingly for deployed linux machines for authentication.
- Lori runs sponsor_resources and accounts-client manually, at whatever interval
- whenever she knows there are changes to deploy;
- month end for billing charges;
- term-switch n-weeks before the end of term
- Lori also runs accounts_master to pull down registrar data manually, at whatever interval (frequently at beginnings of terms).
- Robyn: intentional design of a person monitoring the output of each step to look for syntax errors or new fields the Registrar added without telling anyone, which require parser changes. These are intentionally not automated.
- They can infer from experience that not all the steps happened, need to fix and re-run...
- sponsor_resources output warns about batches of expired sponsorships; Lori then needs to go into source files and remove the people manually. We walked through removing a sponsored research account for a grad student; while the account still exists, since it's expired, it automatically has been given a non-login shell.
- NexusComputerGroups and NexusComplexGroups define the Nexus and SCCM groups and computers which associate the groups to account classes (groups). This suggests we can leave aside pulling this directly into the database; if they update SAT with equivalent group names, the pairing will still work.
- they will use our API to pull results from SAT instead of extracting from the flat files.
- They use classlist files to populate access lists in Active Directory - they would use our API to output an equivalent list of users (Isaac has already working on a ticket to report classlist data replacing the flat files).
- it is unclear how the classlist files are turned into Active Directory Security Group members; the process is equivalent to Clayton's updates.
- Sample error conditions:
Fatal error: "/software/accounts-master/data/sponsors/REGISTRAR/Undergrads" line 81: Unknown member "*"
Error: "/software/accounts-master/data/sponsors/REGISTRAR/Undergrads" line 27: Can't find userid for id number '*:20811267' - supplied student ID has no watiam associated.
- When do they have to go back to IST for a fix? One is when someone has more than one watiam ID. eg., they were a student, and now they're staff, and HR doesn't use the old userid. They have to be merged by IST.
- our uid registry will complain about non-standard uids.
==== checking id registry status ==== Fri Feb 12 13:15:22 EST 2016 Host has non-standard uids: /etc/passwd: rstudio-server:82
- I brought up how the new system will be much more automated.
- Robyn raised: what if Lori is changing a number of class names related to one thing, and wants them to take effect when she's done, rather than immediately.
- Or if edits introduce an inconsistent state, and has potential for causing damage. Jim's scripts run every 15 minutes.
- suggests he wants a "pause" button.
- term switch and month-end billing (pulling in data to create statements - which uses the data we've revamped; and they will need to rewrite in order to use).
Some takeaways and questions
- new request: potential for transactional batch updates, which must happen at the same time. (none happen until ready).
- would 1-day granularity help? No; some changes could conceivably be multi-day work.
- how about prepping a batch update via a CSV instead?...
- I think Jim's scripts can exist outside our code, for now. Rely on group names matching up.
- MFCF does monthly billing which requires pulling stats from accounting system. Will require rewriting their scripts.
- Lori and her student employees do a LOT of manual updates. eg., removing entries post-expiry.
- how many of their error conditions would still happen if fed latest watIAM and classlist data? Already pre-vetted by OAT import?
- they don't make tickets for requests- should I try and get a look at some sample emails from their users? Probably not necessary at this point.
2020-09-30
Webdev checkin Discussed yesterday's meeting with Lori and Robyn.- It was useful to see the current workflows.
- One question is about the request to "pause updates" to allow for batch changes all at once. What specifically would need this feature in the new system?
- It seems likely that a lot of the use-cases are already covered by auto-imported data.
- Robyn's request was "don't do an update tonight" - but it's not clear how that's compatible with the overall data model of frequently imported data and all-campus usage (what if one unit wants changes immediately and another wants changes deferred? The changes could cover the same CS/Math users...)
- Discussed one possible solution: via batch-import from text-file, for the things which have to happen at the same time.
- Another (more complex) solution is like a git commit, where batch changes are somehow staged.
- It looks likely that Jim's scripts can exist outside our code, for now. Rely on group names matching up; and using our API to report the details to Jim's scripts.
- MFCF does monthly billing which requires pulling stats from accounting system. Will require rewriting their scripts.
- he will work on the auto-update of computed groups
- First steps: Daniel and Niya looked at the web UI; which currently doesn't load the people section, or for assigning people to groups. This needs fixing.
- Looked at the wireframe
- Can we perform user stories using the wireframe? Possibly. Daniel to write up yesterday's meeting notes and then we can work on user stories.
2020-10-01
User Stories discussion Daniel and Niya created detailed user stories- Wrote out user personas, what users want/need, and what we need to include in the UI
- Currently existing
- Adding single/multiple users to a group/groups
- CSV imports
- Viewing of user details
- Automatically create groups
- Need to create
- View user history
- Daniel to fix web UI for viewing users and viewing group members, so we can examine them more closely. [ done ]
- Learn MFCF monthly reports process- how does it interact with database? [ in process over email ]
- Request more data from MFCF about user requests, so we can create additional accurate user stories. [ see further notes from Daniel on 2020-10-02 saved to SATAccountsUserStoriesData ]
- Discuss UI changes that currently do not exist and look at existing UI
2020-10-05
Daniel and Niya: Discussion of Transactions / Comments / History Core motivations:- As a user editing data, they should have every chance to record why they did something.
- As a user looking up data, they should be able to easily check on why someone else did something, including if it was done by automated changes.
- As a user looking up data, they should be able to see all transactions that might be related to their lookup, in all places that might be helpful.
- At the same time, they should be able to search and filter out data they don't care about.
Comments on Comments
Comments are always attached to a transaction where a change was made in the database. Always store comments with the related transaction. We can add two fields, prominent on edit pages. [ RT#___ ] [ Comments___ ]- Both are optional. Ideally only an RT# is necessary, but sometimes there isn't an RT#, and/or sometimes an additional comment is needed.
- Possibly a 3rd button: [ clear comments ]
- So that on saving a change, RT# and comments are kept for the next change as well.
- keep on all saves (user-saves, group-saves, resource-saves, etc.) until cleared.
- So that on saving a change, RT# and comments are kept for the next change as well.
- possibly, instead of 3rd button, a more complex "git commit" version:
- replace 3rd button with "[ do as batch ]" and it somehow holds off before submitting them, tracks between comments, such that edits to the comment will update for all.
- probably too complex and unecessary. Recording the idea in case we aren't happy with the other options.
- we may learn that people don't want the 3rd button or remember to clear the comments... Prototype with/without 3rd button?
Transactions
2020-11-24 updates to this spec to remove "automatic" transactions. Those will be handled in a separate display of the historical values, details TO BE DETERMINED. Transactions are visible on just about every page, to show manual update history that is relevant. On user-display page, "transactions" section will include one row per transaction. Columns:| timestamp | action | action-on | old-value | new-value | actor | RT# | Comments |
- Descriptions and details
- timestamp is recorded to the 100th of second? but displayed only to the second. In case there are sub-second update occurances we're sure to see the correct order.
- action is the stored procedure used - either just the stored procedure name, or a human-readable version.
- (Do we need a table of stored procedures and their human-readable titles, such as "Create customer" instead of "sponsor_customer_create" ?)
- action-on is the person's name, or group's name, or "group x resource y", or sponsor name ...
- old-value is blank for additions to group; new-value is blank for removals from group.
- optional RT# is a link, if it's been filled in. Possibly we can display the RT title text using our direct RT SQL lookup.
- Comments are optionally supplied by the user
- Possibly can be filtered? Or filtering is only done on Transactions page (see below)
- table can be re-sorted and filtered.
- by default, includes all transactions affecting the group, including manual additions and subtractions from that group.
- checkbox for "show member changes" is checked by default
- unchecking dynamically updates the page.
- by default, includes all groups.
- implemented by doing a text search for action-on matching the resource name
- this is arguably a questionable design-
- what if a resource name matched a group name?
- But if the alternative is to replace "action-on" with hard-coded columns; or supplementing "action-on" with 1:many relational lookups for user, group, resource, sponsor, or billcode; both of these alternatives sound overly complex.
- this design relies on postgres efficiency of text searches.
- But I think we want to allow users to do a text search of various fields.
- So this feature isn't "worse" than the text search we want to offer them anyway.
- If the choices are between a redesign for "action-on" with a more complex structure, or leaving out the display of Resource transactions, I'd leave it off and just allow users to to a text search on in the "Transactions" section.
- what if a resource name matched a group name?
2020-10-06
Daniel and Niya: Discussion of Transactions / Comments / History (continued) We reviewed "Comments" as described yesterday.- Niya will prototype code that illustrates two options for editing groups and group-members:
- two fields, Comments & RT#, which auto-blank after every change (added/edited group; added/edited/removed group member)
- three fields. Comments & RT# text stays filled in after every change and page-change; "Clear comment" button blanks them.
- We will then review with some end-users to learn if there is consensus about the UI before we plan for database changes.
- Most pages should have a history section.
- When we discussed transaction details, we raised more questions...
- We need descriptions for an assortment of stored procedures for illustration purposes.
- eg., we have
group_member_insert("group","person")illustrates action = "Add Person to Group", action-on "group", new-value = "person" - we'll need an equivalent which includes parameters for active dates... how do we show the active dates in the transactions table?
- eg., we have
- Daniel to suggest some possibilities with Isaac.
- We need descriptions for an assortment of stored procedures for illustration purposes.
2020-10-07
webdev checkin- Daniel to send Isaac possibilities for stored procedures in the API RT
- discussed some options for recording transactions/history. One transactions table, including columns for various procedures' options as columns (as above).
- Question: what about groups-of-groups; we're not recording nested changes, are we? No; but in the UI we're already traversing the tree to report to the user about nested groups, so we can look up history for each at the same time. Also, Isaac notes we are recording an explicit list of all group memberships.
- Either Isaac or Daniel will make the stored procedures, for use by web UI and by command-line tools.
- discussed some options for recording transactions/history. One transactions table, including columns for various procedures' options as columns (as above).
- Niya to continue prototyping UI for user-testing on Comments
2020-10-14
webdev checkin- Niya and Daniel; further work on recording Comments/RTs in /RT#1105414 including meetings with Gord and Harsh for user-testing options.
2020-11-05
Notes from Daniel, for discussion with Isaac (along with stored procedures in the API RT). See #2020-11-24 for updated version. Draft Transaction Log table, based on SATAccountsRequirements#Transactions above.
CREATE TABLE transaction (
transaction_id serial NOT NULL,
PRIMARY KEY (transaction_id),
transaction_time timestamp NOT NULL,
action text NOT NULL,
action_on text NOT NULL,
oldval text,
newval text,
actor text NOT NULL,
rt_id integer,
comment text,
automatic boolean DEFAULT FALSE
);
Comments -
actionis either the name of the caller stored procedure, or a human-readable version of it. (to be determined; I think we can go with just the name of the stored procedure. Such as "group_member_insert" rather than a more human-readable "Add member to group") -
action_onis the field being updated -
oldvalis blank for additions to group;newvalis blank for removals from group. - for automatic updates, I'd like to see a
comment"Automatic update by [ process ]" along withautomatic TRUE
- how do we obtain the oldval? Does the caller need to supply it, or can the transaction logger look it up?
- how do we obtain the actor? Sometimes it will be the postgres user (eg., calling the API function from a command-line application). But the web application will presumably be a single user.
- In previous discussion with Isaac and Niya, I suggested a single line in the transaction log for updates. This is not sufficient- the right answer is a line in the transaction log for each change.
- As a basic example: many of the proposed stored procedures have more than one parameter supplying a change. Either we need a pair of columns in the transaction log for each possible parameter (old and new value), or we store one transaction per changed parameter.
- Looking at draft function sponsor_region_create_or_update, on "create" there would be two transactions:
- action_on = "region", oldval = "", newval = the new region name
- action_on = "admin", oldval = "", newval = the new region's admin name
- On "update" there would be one transaction:
- action_on = "admin", with supplied oldval and newval
- so in addition to the above two questions, there is a third question: how do we know whether our change is a create or update? There may be a clever postgres feature for this; or we may want to split apart the functions into "sponsor_region_create" and "sponsor_region_update"
2020-11-06
Meeting between Daniel, Isaac, Niya, and Anna We went over most (all?) of the outstanding database questions. Isaac clarified an important database feature: a group member can have multiple historical active-date ranges which means:- Deleting someone from a group is setting the active ending date to today. Adding them back to the group adds a new row, with a default active starting date of today.
- that implies automatic updates of group membership don't need transactions; since all of the relevent information is stored in the group_member table. There isn't any point to recording comments or actors on group membership updates; in fact, trying to make an intelligent comment about why an update happened, is more difficult than Isaac wants to consider. Fair point.
- that implies the web UI for viewing group and person history will have two sections; a historical record of their group memberships as automatically updated, and a transaction log for manual updates.
- Noting that there can be manual updates of group memberships, which will have a transaction recorded, and potentially RTs/comments.
- the transaction log might not need a flag to record "automatic" transactions, though perhaps it will be useful for batch updates by command-line users.
- Daniel to ask potential users, what batch updates might you be doing from the command-line? (recognizing that student group updates are automated).
- Noting for the record, it will be nice when we can access HR data for appointment start/end dates; this would automate a batch of additional tasks.
- Isaac will do these schema updates, after he's worked a bit more on automatic group changes.
- how do we obtain the oldval? A: the transaction logger should look it up.
- how do we obtain the actor when it's the web application? A: we can have a stored procedure to
SETa custom variable used for the session (so, the entire web transaction, not just the postgres function call). It will set the REMOTE_USER at the beginning of the web transaction, which can be automatically included in subsequent function calls.- Agreement that command-line API-calls should use user-specific accounts, so we can record the actor.
- We'll discuss implementation after we have the above schema additions.
2020-11-11
Meeting between Daniel, Lawrence, Niya Gave Lawrence a demo of the latest changes since he last saw it.- Q: is it possible to fill in comments after they user has started saving changes?
- A: we were looking at that, but it might be complex. For example, how do we know what actions to "back-date" the comments to? Everything they've done? What if they didn't mean everything?
- followup after thinking about it: we could allow adding/editing comments on a user's own actions. It could be a special feature on the Transactions Viewing page. We can keep this as a wish-list item to look into later in available time.
- Q: can we make it more likely they remember to fill in a comment? Empty comments/RT: prompt them? show as red?
- A: yes, we had more or less the same idea!
- Note for additional user-testing: options for adding start and end date specifics, for things like Sponsors and Billcodes. Offer them everywhere, or do we just give them "delete" and make the start/end dates an advanced edit function?
- Q: when they are making updates from the command-line, how do they add comments? Could we support using the same comments on multiple command entries?
- A: the initial design is a simple command parameter. Perhaps the end-user command could check a shell variable?
- Q: in the old system, term additions happen in advance. If we're adding users to groups automatically, when do accounts get created? In particular, for TAs and profs?
- A: this is controlled by the start dates. There is a different automatic group set up for instructors of each course, and the start date for instructors could be programmatically set for weeks or months before the term start. We need to go over this in detail with Infrastructure.
2020-11-18
webdev checkin- UI demo from Niya; brainstormed RT/comments improvements.
- Database update: Isaac's nearly done with schema updates, which add active dates. He will create one or more sample stored procedures, and we'll meet Friday afternoon to discuss.
- After that, I will book a meeting with the project team to discuss infrastructure implementation
- Discussed how web UI / stored procedures can handle username, RT/comment via
SETand custom postgers variables as described above on 6-Nov. So we don't need to add them all as parameters.- Command-line tool can call a wrapper around stored-procedure, looks for: 1) command-line specified RT/comment; 2) otherwise check for unix env variable
- Given groups corresponding to all courses, for both students and instructors, which are automatically updated
- What manual command-line updates will you need, particularly those that don't fall into the pattern of "add user X to group Y with these start/end dates"?
2020-11-20
Meeting between Daniel, Isaac, Niya, and Anna- To discuss progress on stored procedures and schema
sponsor_customer_create and sponsor_customer_delete - chosen for their simplicity. - and they raise interesting questions, noted below.
- including active dates will allow(but not require) multiple historical active-date ranges as described on 2020-11-06.
-
DOMAIN daterange_activewhich is a daterange type plus a default value(current_date, null)and constrained to NOT NULL - And a trigger which will automatically delete data rows which have an empty range (start and end dates are the same).
- which will be the default for all SAT tables.
- Q: what if a user set the start/end dates to the same thing accidentally? A: for some stored functions, the user can't- we're not exposing the dates everywhere, just where it makes sense. Isaac says it doesn't make sense for
sponsor_adminorsponsor_customertables; we just let the user issue "create" or "delete" and set the start and end date automatically.- As far as users are concerned, the customer exists or it doesn't. The dates are not exposed unless we're looking at an audit-history.
- Q: how about the use-case of creating a customer who starts being active in the future? A: Isaac doesn't see why we ever would. What's the use-case in the real data? (creating a sponsor who isn't available yet?) TO BE DETERMINED.
- Q: how about a use-case of creating a customer who became active at a time in the past, eg., importing? A: if necessary, we could manually update that data. Probably not useful/necessary beyond first setup. TO BE REVISITED if necessary.
- Q: what about the stored functions where the user does need to set start/end dates? A:
TO BE DETERMINED. Will discuss later (when we have examples of those functions). - Q: what happens if the customer is deleted (manually or automatically) and they have associated billcodes, which have associated sponsorships? A: TO BE DETERMINED.
group_member_insert and group_member_delete. - By default these functions set the start and end dates automatically (as above).
- Isaac's suggestion is that
_insertwith a specified date-range will create or expand the date ranges and_deletewill restrict the date ranges. - But we want to be able to allow the end user to assert "make this person a group member for this start and end dates."
- Isaac's suggestion is that
- Q: what happens if they assert a date range that overlaps with an existing range? Does it change the existing one, or fail because it conflicts? A: Since this is a fairly complex operation, we may need to use the 2nd option, for now; adding more flexibility later.
TO BE DETERMINED. - Isaac notes that changing dates in the past (changing history) is different than changing dates in the future (changing plans).
- Q: do we need to allow arbitrary history changes at the user level? Why? Do we need to accomodate all kinds of complex multiple active ranges in the future?
TO BE DETERMINED
- Q: do we need to allow arbitrary history changes at the user level? Why? Do we need to accomodate all kinds of complex multiple active ranges in the future?
- The design including multiple historical active-date ranges for all kinds of data is very helpful for not losing "deleted" data. It also adds complexity to any table where start/end dates are meant to be updated by administrative users: group membership, diskquota, login, user-group, mail-alias. Do we need more than one active row in each table? Taking one example...
- Is there a requirement that we allow setting diskquota at different values at different current or future time-periods? Or is it sufficient to have one current value but record history?
- Is there a requirement that we record the diskquota history in the same table, or can we rely on the transactions table for that, and simply record a single diskquota that is set by the user?
2020-11-23
Meeting between Daniel, Isaac, Niya, and Anna Isaac reported on automatic group-of-group membership updates. He plans to split group-membership into two tables, one for "current/history" and one for "planned"; such that computed groups will calculate more easily.- Q: do we need arbitrary future group-of-groups computation? Isaac doesn't plan to compute them in advance. We looked at a few examples.
- "instructors for CSxxx for next term" is represented by a sub-group which is set up and auto-populated for the term. We do not need an "Instructors for CSxxx" supergroup where we specify the date in question.
- But "who are the members of research group X as of date Y" is a question we will need to answer, regularly. (Noting: "research group X" will definitely contain sub-groups, since each sponsorship requires a different sub-group. So we do not completely avoid needing to compute future groups)
- stored procedures where a user needs to set start/end dates: we can set the start/end dates directly, to create or update the existing entry.
- asserting a date-range that overlaps with an existing range: can't happen. There is only one.
- In the general case, deleting is setting an end-date, not deleting the row of data; the billcode can still exist in the database without violating integrity constraints. Do we want to propagate the end-date change, to the billcode and then to the sponsorships? Probably.
- As of right now, the web UI doesn't display effective-dates for customers or bill-codes. But it does for sponsorships.
- In the special case of deleting a customer on the same day as it was created, it would actually delete the data, and presumably delete any sponsorships.
- Or if someone goes to the trouble of creating a batch of bill-codes, then deletes the customer, should it instead refuse to delete the customer because they have active data?
- To be discussed with more end-users.
2020-11-24
Notes from Daniel on the Transaction Log The UI will offer a relevant transactions log on many pages, based on SATAccountsRequirements#Transactions spec above which explains fields from a UI perspective. Here's an updated draft table as a basis for discussion.
CREATE TABLE transaction (
transaction_id serial NOT NULL,
PRIMARY KEY (transaction_id),
transaction_time timestamp NOT NULL,
action text NOT NULL,
action_on text NOT NULL,
oldval text,
newval text,
actor text NOT NULL,
rt_id integer,
comment text
);
Comments -
actionis either the name of the caller stored procedure, or a human-readable version of it. (to be determined; perhaps we can go with just the name of the stored procedure. Such as "group_member_insert" rather than a more human-readable "Add member to group") -
action_onis the field being updated -
oldvalis blank for additions to group;newvalis blank for removals from group.- oldval will be supplied by a lookup by the transaction logger (somehow!)
-
actoris intelligently determined as described on 2020-11-06 - Very likely there needs to be a row in the log for each field change (not just one row for each stored-procedure call).
2020-11-25
Meeting between Daniel, Isaac, Niya, and Anna. Isaac demoed working stored procedures on dev server port 5503:
odyssey=> select sponsor_customer_create ('WatFORM');
[returns numeric ID]
odyssey=> select sponsor_billcode_create ('[same numberic ID]', 3002, 'WatFORM billcode'); -- 3002 is a customer-id
[ returns 1 ]
odyssey=> table sponsor_billcode;
[returns populated billcode rows]
odyssey=> select group_create ('manual_3', 'Test Manual Group 3', 1020); -- 1020 is a maintainer-id
[ returns numeric ID]
odyssey=> select group_member_insert ([same numeric ID], [a person_id] ); -- adding member to the manual group
odyssey=> select group_auto_create ('auto_3', 'Test Auto Group 3', 10); -- 3rd parameter is the "level", which must be specified.
[ returns numeric ID]
odyssey=> select group_auto_member ([same numeric id]);
(0 rows)
-- manual insert into group_depends to make the manual group a member of the automatic group
odyssey=> select group_auto_member ([same numeric id]);
[ returns the manually added member from the sub-group ]
odyssey=> select group_member_insert_future ([manual group numeric id], [a person_id], daterange ('2021-01-01', '2021-05-01'));
- reviewed
group_member_futuretable, similar togroup_memberwith no pkey restrictions on member_active dates, and does not have triggers that recalculate active memberships or delete on empty daterange
- Daniel will book a team meeting.
- discussed transaction logging, which is a follow-up step to implement. Isaac says possibly a draft by Friday. Briefly looked at SATAccountsRequirements#Transactions spec.
- "action" column: record the stored procedure name, and if we need, we can add a lookup table afterward.
- Q: what does it mean to display a list-of-groups? There will be thousands. The UI will need filtering before that list is useful. A: agreed; will need filtering.
- Version 1.1 could automatically filter based on the user. (One idea for this was written up in the requirements for SAT).
2020-11-27
Meeting between Daniel, Isaac, Niya, and Anna. Isaac walked through his test.sql to describe functions. Following are notes which will be more useful when we have the schema available in git, which may be Monday. Customer:- customer is available across the database.
- a change/feature from the old system is we can support one customer in both MFCF and CSCF data.
- they would have different billcodes for each.
- group name is unique. group_description is optional and non-unique.
- open question: group name formatting for all the automated groups. TO BE DETERMINED.
- level = 0 for manual groups.
- automatic groups: can only depend on groups whose levels are lower.
- (recommended increment by 10s to leave room for insertions)
- update a group's level: cannot set it to higher number than any of the dependencies, or lower than any dependent.
- automatic groups are only composed of other groups, not members directly.
- Will require UI implementation
- Q: do we ever need a singleton group named for one person?
- A:
TO BE DETERMINEDtalking with clients. - Isaac asserts most of these cases will be better satisfied by a group that's named for what it's doing, not the person currently doing it. So it can be assigned to someone else when they are doing that thing.
- Daniel asked about a case of CSCF testing vault access. Isaac suggested group "vault load testing".
- the question isn't whether it isn't possible in the UI; can manually create groups for a person. It's whether the process should be facilitated.
- A:
select from group_current where name = 'whatever';
2020-11-30
Group meeting with Dave, Adrian, Clayton, Robyn, Lawrence, Isaac, Niya, Daniel. Agenda- Update on SATAccountsAPI
- Q and A discussion
- Q: To identify who should have an account and "is a student" - what's the definition of "is a student?"
- A: a computed group of all users in whatever Math plans make sense. The computed group can include all users in the past two terms to match the current 2-term grace period.
- Q: Where do home directory paths come from?
- A: Not currently in the odyssey/SAT database. Since this isn't likely to be something you'd modify for individuals, it's probably best done programmatically.
- Noting: currently these are recorded on a regional server, and INF intends to move away from doing that.
- Also noting: Robyn indicates Math (CS/MF) are the only campus groups currently doing our own disk storage. Others are using OneDrive which offers 10tb per student. We don't currently have plans to mount that storage in our environment, though.
- A: Not currently in the odyssey/SAT database. Since this isn't likely to be something you'd modify for individuals, it's probably best done programmatically.
- Q: Are there SAT groups representing sections of a course?
- A: Not currently. If the need is to separate courses by content, Isaac currently has the ability to separate them in Odyssey.. If the need is to split apart roughly equal sized sections, we can talk to Dave/Clayton about what kinds of data is needed...
- Q: Should individuals' accounts get a SAT unix group named for them automatically?
- A: no, the Active Directory system can create them automatically.
- Q: a change/feature from the old system is we can support one customer in both MFCF and CSCF data. This is OK?
- A: yes, as far as we can determine today. (considering that billing is actually done via the billcode and we don't have to worry about billing CS users).
- Q: do we ever need a singleton group named for one person?
- A: not automatically.
- Q: what is Dave's requirements for deployment?
- A: they are using parts of the odyssey lookups already; development will continue at as fast a pace as possible, but it's not needed to be deployed this December.
2020-12-02
Meeting between Daniel, Isaac, Niya, and AnnaTransactions table
We discussed the transactions table. Isaac is going to make a draft implementation substantially different from the one described above. A row will have columns for each possible function parameter. "Old value" can always be computed from the previous relevant transaction. We will hold off and discuss this after he's made his prototype, which he hopes to have for Friday.UI
Niya is implementing resources as spec'd. She's finished the section for unix groups; has to do the one for login groups. Discussion of React and Flask: The current implementation uses SQL Alchemy, which adds a layer of conversion to make the UI work with the new database. Is this necessary or helpful? Can we do Flask with minimal duplication of effort, such as auto-discovery of the schema rather than laying out the schema in code as well as in the database? Daniel to dig into these questions. Discussion of front page. Not just a search box. What will be helpful?- We know from early client discussions that a lot of use will just be lookups of an individual and their details.
- When we demoed with Lori Suess, the topic of a "helper wizard" came up, to prompt step by step what to do.
- Isaac suggests the front page could report on what the user has recently done (from the transaction log).
- adding a person to a group
- adding resources to a group
- editing group definition (to change computed group composition)
- I've done work into mapping non-teaching resources into groups, and I have to get those recorded in a ticket... But I know there will be lots of imported groups with names specified by their unix-group name and not by what they do.
UI for prompting step-by-step on tasks
A user wanting to add resources to a person may need to be prompted with:- what groups already supply these resources?
- is one of those a group this person should be added to?
- if there is a clear answer, add the person to that group.
- if there isn't a clear answer in existing groups, check what groups is that person already in.
- are any of those groups improved by having this additional resource?
- if there's a clear answer, grant the resources to that group.
- if there isn't a clear answer in existing groups or the person's groups, make a new group named by what it is for (not what the resources are...)
- How do they easily tell what other groups might fit?
- Are they clicking into each group to find out the definitions, memberships and resources?
- How many clicks does this require?
- That would require turning the group into a computed group consisting of the union of two sub-groups, then granting the resource to the proper one of the subgroups.
- This would require creating a new computed group consisting of the other group, and assign the new group the specific resources necessary.
2020-12-04
Meeting between Daniel, Isaac, Niya, and Anna Niya is done with the current batch of Resource UI changes, and is working on left-hand menu additions such as Filesystem, Region, and AdminReimplementing Groups UI with F2020 schema
Comparing the existing UI against the new schema, I believe we can proceed without a lot of UI changes in a way that keeps things simple. Changes from existing:-
/groupslist of groups: change "Current Group Contact" into "Group Source" - show "Group Maintainer" values: "Manual", "Automatic", "Odyssey". -
/groups"add group" button: "Parent Group" field needs to be wider to accomodate longer names. Remove start date/end date.- Parent group field will auto-complete the names of automatic groups
-
/groups"edit a group" : we'll display the "Maintainer" column; otherwise no changes. -
/groupdisplaying within a group: remove the "Group Info" section including "Save Changes" (those are part of bill-code now). Also remove "group contact person".- if it's a manual group, Members has no changes.
- If it's an Odyssey group, show a table under "Members" which is read-only, so removing the "Add new member" and "remove" buttons.
- if it's an Automatic group, duplicate the "Members" section twice; in order, the sections should be: "Sub Groups", "Excluded Groups", and "Members" (which is needed to display members of all sub-groups).
- Sub Groups: show a table listing the relevant sub-groups from
group_dependstable. Where the UI currently has "Add new member", it instead has "Add Sub Group"- For each sub group, just as with manual groups, there are "Dates" which are editable and a button for "remove".
- underneith "Sub Groups" add a second table "Exclude" listing excluded groups, with a "Exclude Sub Group" instead of "Add new member" and dates and "Remove" as above.
- When fully implemented, it can automatically set "level" to increment by 10 for new sub-groups, and change the level appropriately if the parent group is changed.
- "Members" is read-only, so removing the "Add new member" and "remove" buttons.
- Sub Groups: show a table listing the relevant sub-groups from
- This will be a first round of UI changes for demoing and user-testing.
2020-12-09
Meeting between Daniel, Isaac, Niya, and Anna Abbreviated notes; I was interrupted by a fire alarm, which seems to have erased my short-term memory of the fine details!... Isaac reported on transactions log work. On two areas we discussed (multiple future date ranges and potential for an "update" function) I will note from 2020-11-23 that we did come to this agreement already, for all tables not just group membership: We will allow one active date-range as described on the 20th. This greatly simplies a number of questions that were "TO BE DETERMINED":- stored procedures where a user needs to set start/end dates: we can set the start/end dates directly, to create or update the existing entry.
- asserting a date-range that overlaps with an existing range: can't happen. There is only one.
- is it true that the transaction log can be reversed to produce the function-call that would have the same effect? If so, that's helpful for a few things including potential batch-transactions. TBD when we have transaction log complete.
- given text file RCS going back to 2003, we could possibly programmatically convert some or all history into proper transactions. This might or might not be feasible. But a question for users, what kinds of history are important to preserve? TBD.
- also from the notes on 2020-11-23 above: how should we handle deleting just-created records? A question for users.
2020-12-11
Meeting with Daniel, Lawrence, Dave, Robyn, Isaac, Adrian, Lori S., Clayton, Niya Demo and Q&ADemo
- Filesystems, Regions, and Admin pages.
- Recording RT# and comment
- Resources: Login, Quota, Unix Groups, Mail Alias (removed Printers)
- Lawrence: consider option to save comment(s) / transactions to RT?
- Option for later: "unix groups" may be too limited. Want to record netgroups as well?
- Naming for "unix groups": could be...
- computing group
- resource group
- authorizations
- ...However, not clear how this connects with what clients want to do; TO BE DETERMINED.
- When we discuss non-administrative app access, Dave wants to be sure we cover TA access for the add/drop period of the term.
Requirements Q&A
- If you "delete" a sponsor/customer, they become inactive (changes end-date to today). Similarly if you "delete" a billcode.
- This does not delete their sponsorships. Q: Should it:
- automatically set the sponsorship end-date to today? ("deleting" it)
- Ask to confirm since they have active data? or...
- Require you re-assign sponsorship to another sponsor/bill-code? A: yes. Don't delete a sponsor with active sponsorships.
- This does not delete their sponsorships. Q: Should it:
- If you delete a customer the same day it was created, it actually deletes it; in case of accidental additions.
- Q: Reasonable? Should it log the creation/deletion? A: yes and yes.
- Q: If you made any sponsorships/bill-codes for this customer, should it:
- Ask to confirm before deleting them?
- A: Require you re-assign sponsorship to another sponsor/bill-code?
- Q: Historical non-teaching (research / admin / *CF) data in rcs: might be able to import. What is critical? What is "nice to have"?
- Currently active sponsors/sponsorships: IMPORT
- Expired sponsorships: eg., former grad students; former staff. (time-frame? Last year? All history?) NO
- Printing? NO
- computing resources no longer active? NO
- A: we can look up old data in text-files; no need to spend time importing it.
2020-12-16
Meeting between Daniel, Isaac, Niya, and Anna Daniel has been working on integrating the front-end with the new schema. Some success, though we're far from done.- Will talk with Isaac about _people schema tables (such as people_appointments; found in https://git.uwaterloo.ca/cscf/people-app/-/blob/dev/schema/admin-tools-schema.sql#L143 and onward.
- Isaac notes that we've requested access to HR data which may provide much of the above including appointments, but that won't block us deploying the initital version as we have.
- this might violate the requirement for one sponsor of each group (or require group constraints we don't currently have).
- how would it handle properties for resources, such as quota-size?
- For now, we'll keep this in our back-pocket; might have some utility at some point.
- He requests making the RT/Comments update the RT ticket, like Inventory does with check-out/check-in; perhaps as a future enhancement.
- We can do further user-testing on this; the complexity comes in with making updates that mention a ticket but should NOT be recorded to the ticket; and situations where the number of updates appears as RT email "noise".
- Brainstorming options: what if there was a button for "Save comments to RTs".
- When pushed, it would display a list of all changes made by this user, since the last time it was pressed. We would offer an option to review changesets as follows:
- There could be a checkbox next to each transaction, to uncheck if that transaction shouldn't be part of the RT updates. The comments could be edited on the fly.
- There could be a "Confirm Save" button; pressing it would batch together all changes for each RT, and save the descriptions of changes to that RT.
- When pushed, it would display a list of all changes made by this user, since the last time it was pressed. We would offer an option to review changesets as follows:
- This would require a table for tracking per-user time-stamps of the last time the button was pressed.
- It would help with fixing comments after transactions have been made; which is one potential issue with the current comment-recording UI. To be further considered!
2020-12-17
Notes/Documentation on changes made by Niya over the term:
- Transaction Input Dropdown (Attached to header, triggered when 'Edit' buttons are clicked) RT#1105414
- Component code found in /static/src/components/TransactionInput/transactioninput.js
- Globally attached to header in /static/src/components/Header/index.js
- Files used to create global variable can be found in this commit (Uses Redux Actions and Reducers)
- Figma for component found here
- Save Prompt Component (Shows up when 'Save' buttons are triggered) RT#1105414
- Component found in /static/src/components/Transactions/savePrompt.js
- Files used to create global variable can be found in this commit (Uses Redux Actions and Reducers)
- Figma for component found here
- New Pages in Left Navigation Bar (Filesystems, Regions, Admin) RT#1099846
- Files are in /static/src/components/Filesystems, /static/src/components/Regions, and /static/src/components/Admin
- Currently uses the Rooms template (thus uses the rooms data currently, so when connecting to the new schema be aware of this)
- The table data currently being displayed is dummy data. The fake data files are in /static/src/utils/.
- Headers for Resources (Login, Quota, Unix Groups, Mail Alias) RT#1099846 RT#1099846
- Files found in /static/src/components/resources/.
- The search version of these files are in the same folder; the file names have 'Search' in it.
- The new headers, Login, Quota, and Unix Groups use the same template as Mail Alias, thus when linking to schema, be aware of this
- Groups UI Changes
- The table data currently being displayed is dummy data. The fake data files are in /static/src/utils/.
- Changes still need to be completed for this, and can be found in the twiki (the last /group bullet point)
- Fix to prevent running 'npm run start' upon every change:
- Add to Vagrantfile 'config.vm.synced_folder ".", "/home/vagrant/people/", create: true, type: 'nfs', mount_options: ["actimeo=1"]' on Line 52
2021-01-26
First weekly meeting between Daniel, Isaac, and William to discuss status and answer questions.- Isaac is working on schema updates and anticipates having them done by next Wednesday at the latest.
- William has successfully updated the Filesystem, Region, and Admin pages to use the F2020 schema /RT#1099846
- He is currently working on the Resources and Sponsors pages.
- Daniel shared an Entity Relationship Diagram for the relevant tables. We walked through it together for a status update and to explain data flow.
- Hm, it would be nice to have a wall-mounted copy where we've coloured in all the tables that have been succesfully converted...
- Updating Sponsors pages requires converting sponsor_sponsor table references into sponsor_customer, affecting many tables (all the right-half of the diagram)
- We need a ticket for converting billcode table to include all of the properties that moved from sponsor_sponsor. /RT#1133145.
- The ERD will be very helpful for the conversion.
- William has made good progress; and will ask as questions come up.
2021-02-02
Meeting between Daniel, Isaac, and William to discuss status and answer questions.- Isaac has pushed one schema update with a helper-function to reset role permissions. He will make a bigger schema update with functions later today; and will leave the dev database with test data in it
- William is working on Resources.
- Daniel will make a ticket specific to data-import.
- Isaac will assign one of his co-ops to work on this, with discussion with Daniel
2021-02-16
Meeting between Daniel, Isaac, and William to discuss status and answer questions.- On Friday, Isaac pushed his bigger schema update with (all necessary?) stored functions; including logging.
- up-to-date on odyssey-dev-1 port 5501 - demo server
- William has made progress on Resources, updating the working schema to the (pre-Friday) version, and hooking in all the resource types.
- remaining in Resources: changing over "sponsor_id" to "customer_id" and some data-lookups that currently use redux that will be faster without. Est. 2-3 days work remaining on that.
- we wil switch tasks: the Sponsors and Billcodes sections are going to require updates throughout the app, and completing them are necessary for Resources as well. Est. 2 weeks.
- would it be helpful to have another worker on this? Not at this point.
- however, two areas not yet started, could be done by someone else: Groups /RT#1120910 and userinfo command-line tool /RT#1106283
- Daniel set up /RT#1134878 on data-import.
- Daniel, Isaac, William Tran and Ryan Deng met to discuss it last week; Daniel gave an overview of the schema changes
- describing the data-import tasks was difficult, in part because there wasn't sample data.
- Isaac has populated odyssey-dev-1:5501 with the _old data so Daniel can proceed with describing the import tasks (then follow up with Isaac about assigning a co-op).
- Daniel, Isaac, William Tran and Ryan Deng met to discuss it last week; Daniel gave an overview of the schema changes
2021-02-23
Meeting between Daniel, Isaac, and William to discuss status and answer questions.- Confirmed: Daniel to ask Ryan to help with data conversion.
- We don't have a chart mapping between old and new field-names, just ticket comments. Daniel to start one and assign it to Ryan to work on.
- Confirmed: Daniel to grant _math_computing_root to drallen, y95deng
- Stored functions are for in-production (and later in testing).
- Isaac notes that stored functions don't allow back-dating start-dates. We've discussed earlier, that is likely OK for user functionality
- will need UI tweaks so users don't try and change history.
- Isaac will document setting the three required global variables.
- The database (v.9.5) is missing a helpful feature he used which set the defaults.
- He will leave it as-is but when we deploy the upgraded database, it won't require manually setting the variables.
- The database (v.9.5) is missing a helpful feature he used which set the defaults.
- Questions from William:
- Does group_maintainer have a source in our data? A: No; all of the imports will become "Manual" - and potentially we will be figuring out some that are "Automatic".
- What changes need to happen for groups? Do we have a writeup of this? A: See https://rt.uwaterloo.ca/Ticket/Display.html?id=1120910#txn-25280589
- Does group_sponsorships exist in the new database? A: No; it's replaced by sponsor_customers and we don't need the old data.
2021-03-02
Meeting between Daniel, Isaac, Ryan and William to discuss status and answer questions.- William's update - a few days of work left on Sponsors; estimate a total of two weeks work left on UI conversion for schema.
- Ryan's update - have met with Daniel; is reviewing the mapping chart Daniel started last week. Asking good questions:
- Q: how is billcode_seq defined?
- A: row_number window function - take a look at https://medium.com/analytics-and-data/the-versatility-of-row-number-one-of-sqls-greatest-functions-53ec78e74096
- A: row_number window function - take a look at https://medium.com/analytics-and-data/the-versatility-of-row-number-one-of-sqls-greatest-functions-53ec78e74096
- Q: sponsor_admin has two hardcoded values, MFCF and CSCF. Are we only populating CSCF?
- A: At this stage, yes. We'll populate MFCF afterward.
- Q: mapping chart refers to ticket which says there are 9 regions. His query of the data reports 17 computing_names (regions). Why?
- A: Since August, Adrian has been adding new regions, apparently for testing purposes. For completeness sake, we should use the list of 17 as valid region names. It may turn out that we'll want to delete some which are for testing, but it makes sense to populate them all for now.
- Q: how is billcode_seq defined?
- discussed populating multiple tables at once? potentially using "WITH" query. Probably better to do one-by-one with a temporary table. Possibly with interim calculations in temp table(s).
2021-03-16
- Ryan has questions about diskquota and filesystem data - any diskquota is currently associated with a region, not a filesystem.
- We could try and import what we have and try and make guesses about filesystems, but it's unclear how useful that would be since we don't enforce quota.
- So we'll leave filesystem and diskquota unpopulated for now.
- William: work proceeds!
2021-03-23
- Ryan has imported tables except for filesystem/diskquota, which depends on implementation. (and on 2021-03-18 we decided to leave them blank until we have an implementation).
- Ryan is now working on data validation via userinfo samples.
- William: resources page last week; almost done. Will do check-in soon; and Daniel to review and assess where we're at.
2021-03-30
- Ryan has done two iterations of data-validation with userinfo samples; Daniel has reviewed the first iteration and will give feedback on the second iteration today.
- 2021-03-31: which has led to a third iteration of data-validation, and questions for Isaac and Adrian about data apparently not matching between userinfo and the old mysql import.
- William: resources done (and code reviewed); regions page done and checked in ready for review; proceeding with filesystem then admin; then starting on groups pages.
2021-04-06
- William is working on groups pages and database. Daniel walked through the schema changes and pointed William at prior notes here; then he and Daniel to discuss implementation.
- https://cs.uwaterloo.ca/twiki/view/CF/SATAccountsRequirements#2020-12-04 group UI
- https://cs.uwaterloo.ca/twiki/view/CF/SATAccountsRequirements#2020-11-27 automated group schema notes
- Ryan and Daniel have questions on data imports; which are in https://rt.uwaterloo.ca/Ticket/Display.html?id=910469#txn-26414497 - on groups that are reflected in userinfo, but are not reflected in the (supposedly identical) 2019 database. We need to either get an answer about the cause, or possibly do a much more comprehensive mapping of other users to determine the extent of the problem, which may or may not be automatable.
- Ryan asked about the extent of groups we do not need to import; Daniel confirmed from these notes that 'away' groups will be automatically generated so we don't need to trace all of them. Leaving fewer discrepencies to trace.
- Daniel confirms that Ryan's definition of currently active in the old data should be correct.
-
WHERE sc.userinfo_userid = name AND (member_ends is NULL OR member_ends > now()) AND (computing_expires is NULL OR computing_expires > now())
-
- Most of the coding work is incremental / can't easily be separated. Perhaps the biggest portion of unstarted work is: code for making updates to the database by stored procedure. Daniel might start working on this, since it's separate from what William and Ryan are currently doing.
2021-04-08
Daniel met with Dave to discuss infrastructure requirements.- (Dave also expects to be available next Wednesday for the group meeting Daniel has scheduled)
- Project timing:
- Daniel says the end-to-end won't be complete in the next few weeks.
- We should have accurate sample data
- We should have the ability to query it.
- We may have limited tooling to update it...
- But we're making progress at a rate that we will definitely have these ready for later in Spring term.
- Dave says: great if the web UI is operational by July/August; if not, he will be sending tickets for accounts changes to Daniel

- Daniel says the end-to-end won't be complete in the next few weeks.
- What does Infrastructure need for implementation?
- Converting Clayton's AD tools to use the new queries versus the old queries; and testing.
- Query tools
- Update tools
- Dave's questions:
- How will CSCF handle fulfilling sponsorship requests before a student is in the Quest data? Currently handled by Adrian. Dave would ultimately like to see this handled by ISCs/course staff instead of CSCF, but it's OK for that to be follow-on work.
- How will CSCF handle sponsorship requests for research groups, the special cases for people who aren't grad students? Anyone in CSCF will have the ability to update these.
- Questions of adding new kinds of queries- will come next term (might involve Anthony).
2021-04-14
Webdev meeting - prep for update meeting at 1pm.- William working on groups pages; he's got a strategy for accessing group parents/children and groups should be ready "soonish" - not this week.
- the majority of the app should work, for a demo.
- Daniel to see if he can get his version working. Will require schema updates- William to provide.
- This morning, Isaac has reset the dev database as a clone of prod, for other work. We agree it would be nice to have more dev databases. He will re-import the dev schema.
- He will let Daniel know if Daniel should do the permission grants for Ryan.
- Ryan has questions about data import.
- Re: [group_group]: should I not import a group if it's in student.cs region, even if it's also in other regions? Currently I am still importing them
- A: groups to not import are courses + away groups. Student regions include student.cs, canadanis, and any teaching.
- For the student regions, please prep a list of questionable groups and we can review them. Example: yes, import 'CSCF601' - not a course.
- A: groups to not import are courses + away groups. Student regions include student.cs, canadanis, and any teaching.
- [sponsor_member_old]: member_starts & member_ends are not imported to the new system, is this OK?
- A: yes.
- [on conflict do nothing] which active dates to keep when overlapped?
- A: use the widest acceptable dates, combine the earliest & latest dates. Note that we can only have one sets of future date in the application
- [group_group] should I still import a group if its member_ends or computing_expires is in the past?
- A: yes.
- [group_group] should I still import groups that do not have members, unixgroups, nor regions?
- Ryan to provide examples after the meeting (once he has access and data again).
- Re: [group_group]: should I not import a group if it's in student.cs region, even if it's also in other regions? Currently I am still importing them
- Daniel reviewed the agenda for the afternoon meeting.
2021-04-14
Adrian, Clayton, Daniel, Isaac, Lawrence, Robyn, Ryan, William Meeting Agenda:- data import progress
- Web UI status
- Given data, what does Infrastructure need for tooling? - reviewed notes from conversation with Dave on 2021-04-08
- CLI app replicating userinfo status (deferred)
- holding off this question until we can demo, in approximately a week
- yes; we'll test the new system using Clayton's AD files for comparison.
- what is the expected process for updating non-watiam course accounts? * used by lots of our infrastructure- eg., markus/marmoset
- Adrian can supply the current list of accounts that are not in watiam (Isaac reports ~900 in student, ~100 in general)
- To be determined: is the number of changes each term large or small?
- We have said previously that this database is meant to be attached to watiam userids;
- See 2019-12-12: "Can we eliminate reliance on non-watiam "userids" accounts, moving them into watiam?"
- See 2020-01-23: "it's currently out of scope to plan for accounts that do not have watiam correspondence. odyssey is driven by the campus user database (with unique internal IDs corresponding to them), and this would introduce another authoritative source (potentially conflicting) that hasn't been implemented or worked through."
- But somehow these non-watiam course accounts slipped through.
- Do we have to make resource changes for these non-watiam course accounts?
- could they be "grandfathered" into existing groups after the database query for members, before the resources are supplied to each member? - such as in Clayton's scripts?
- could we assign them a "person_id" in the database?
- Isaac and Daniel can discuss how we could implement this.
- not going away as far as Isaac knows. IST would have to tell us, with a plan.
- we have most of an import of existing data.
- Isaac has a draft for term-by-term imports - this will need review. And will need additional work by Isaac to make it work with new group hierarchy system.
- Ryan's question about ~100 groups that do not have members, unixgroups, nor regions
- They have class_names such as: Rddc001, Rddc002, CSTest-005, Rnish002, math8 ...
- Followup with Adrian: some are TA groups for courses that didn't have any members. Many (most?) are historic research group placeholders. (eg., Rddc = Don Cowan).
- Perhaps not needed, especially since it will be easy to make new groups going forward.
- In the interest of not importing empty historical records, Daniel's inclination is to not create these.
- Daniel to ask Lawrence and others, once we can demo the app and group creation.
- Tutorial on using the "API" - stored functions to update database.
- Converting Clayton's queries for the new schema.
- Clayton has questions about netgroups, but won't raise them today.
- Daniel noted previous suggestion (on 2020-09-29) that MFCF can keep the sideband data in its current form.
- When their data is imported into SAT, the "Classes" can be converted into "Groups" with the same names as matching in the sideband data.
- Jim's scripts will need to be updated to use the SQL database instead of whatever sponsorship querying it currently does.
- This solution is the least amount of work to implement.
- Robyn asked what if they want to do away with editing text files for this sideband data as well?
- If it's of more general use, we might be able to implement these as additional sponsored resources. However, we don't know what it does; or whether it should be implemented in the app for general use.
- Isaac, Daniel, and Robyn agree that the best way to proceed is to have Robyn ask Jim to document the sideband data and requirements. We can look at the documentation and then discuss possibilities.
2021-04-23
Webdev wrapup status 1-on-1 meetings.- William: groups page is debugged. Removed stale references to "rooms". /group page to view individual group still needs conversion.
- Ryan: data is prepped for import; all appears to work as expected, except a remaining issue with sponsor_mailalias: there is a uniqueness constraint on (group, mail-alias localpart, and active dates). Different groups try to sponsor the same alias/region... Daniel will investigate further.
2021-06-07
Co-op work proceeds, with daily check-ins and updates in tickets. Much progress converting the back-end to use the latest schema and converting the front-end to fit. Today, we held two user feedback interviews, concerning the Transactions page.- We've renamed it "History" in the UI to be more user-friendly.
- This page now uses the latest history_log table designed by Isaac. From that table we must output 16 columns, which introduces a challenge for display.
- The challenge is only for this page, where we cannot assume which columns should be used, as we can in other portions of the app.
- We brainstormed and prototyped five versions:
- first ~7 columns are visible, plus horizontal scrollbar
- first ~7 columns are visible, plus clicking on a row to get additional columns in a popup
- logfile format: first column is date; the rest is lines of text that word-wrap
- vertical table with transposed columns/rows, 4 entries visible, plus horizontal scrollbar
- split table: 4 entries visible, and a second table directly under the first scrolls in sync to show the remaining columns
- Lawrence: works with spreadsheets. For him, the "principle of least astonishment" would suggest the first option with scroll-bar, sorting, and filtering. Possibly selecting only some columns.
- Can we drill down by clicking on a history record? Most logical operation would be showing adjacent actions by timestamp.
- Lawrence imagines filtering by date runs into a problem with "it was roughly a week ago" - how to expand the filter to adjacent entries?
- concept: "remember where you were" when you clear a filter; an important operation in a spreadsheet
- Can we offer a global search (matching any columns?)
- Options with pages: if there are many, we will want a text-field to input a page-number.
- Lawerence is less fond of the last three options. Vertical: small number of entries, and requires a certain height on the page for 16 entries. Split: it's somewhat confusing.
- Debriefing on Lawrence's ideas: "remember where you were" seems very useful, instead of resetting to the top of the data. Use the time-stamp. Both for adding additional filters, and removing filters.
- Harsh: highest preference for second option, and allow users to add columns to the default display. Or the first option, and remove columns. Finds 3) 4) 5) confusing for new users / less technical users.
- Another option similar to 2) would be collapsable/expandable rows. We'll try prototyping this along with removing/showing rows with option 2.
2021-06-08
Following yesterday's user feedback, Daniel got additional feedback from the FAST campus dev group. Excellent comments from six campus devs that validate our decisions yesterday. Interesting questions about the scope:
Interesting questions about the scope: - Pavol Chvala: form factors for phone?
- NOT designing this for small form-factor.
- Kate Wood: do we really need to consider all the columns? Versus just offering the other portions of the app that can have limited columns?
- Yes, we do need this.
- when we expose a dropdown of extra columns, how about a convenience feature to click on an extra column to add it to our display.
2021-07-23
Meeting scheduled with Clayton, Adrian, Dave. Met with Clayton and Adrian. Agenda: Where are we with SAT accounts database for Infrastructure needs?- data import from old schema to new schema
- planning for converting Clayton's queries for the new schema
- Q&A
- database tables that report active groups, and active members of groups. How this can be used by Clayton's scripts as a simple change from the current lookups.
- full import data of non-course sponsored accounts (including login and quota details) and groups (formerly known as classes) - with descriptive names.
- brief web UI demo, but got stuck. We are prepared for a proper web UI demo soon.
- Q: do we have course registrations on an ongoing basis? A: we get this data from OAT, so we have all course registrations known to OAT.
- Q: will we eventually handle authorization of who can make their own edits? A: yes, later, but right now it's CSCF staff.
- will require talking with Teaching admin staff; the rule isn't "faculty members delegate this to whoever they like." We want to go through established processes that keeps the audit trail.
- Q from Daniel: non-watiam accounts are not anywhere in OAT, so that creates issues for handling within the odyssey database. Can we consider adding to Clayton's code to add a side-band list of grandfathered accounts, which aren't visible in the web UI? Adrian asks are we thinking of continuing to run the old accounts code alongside the new? Daniel doesn't think that's necessary.
- Daniel proposes a simple flat file of essentially "CSCF-sponsored" accounts such as course IDs that aren't watiam accounts. If we cannot eventually add those accounts as watiam accounts, we will need to consider a different data model.
- Q: Clayton's request for course section information: status? A: Daniel to ask Isaac. When we last talked about it with Clayton https://cs.uwaterloo.ca/twiki/view/CF/SATAccountsRequirements#2020-08-05, Isaac said he would expose all the groups that odyssey knows about, which will include sections.
- Q: can we expand this to directly operate with netgroups?
- Clayton wants to update network resources such as samba shares- to use netgroups instead of security groups with GID.
- As currently modeled, Clayton could extend his code to create netgroups based on sponsor data, how he currently uses a "net_g" group name. He could also set up automatic groups that are children of a "netgroup" parent. (groups can have multiple parents)
- how about sponsorship of netgroups as a resource type? Clayton explained how netgroups are tuples; profs might want netgroups to sponsor machines, domains.
- nisNetgroupTriple (hostname, username, domainname) - we only populate username
- theoretically we can add other resource types, but we want to know how these will be used. If we see a possible use case, we can go into further details about how this can work.
- Q from Daniel: are we any further on creation and removal of accounts process? A: will need to talk to Dave.
- We have data on expiry dates in the future and past; a username can have many simultaneous sponsorships in the past and present, and can have one sponsorship that starts in the future.
- Easy to queue up "which accounts should be created today, for course-registrations that start soon" for whatever values of "soon"; similarly "which accounts should be deleted today, for sponsorships that expired a while ago" - for whatever values of "a while ago".
- Q: manual sponsorship of users needing an extension into the next term: Adrian receives a list from Karen Anderson. This can be handled by adding them to a manual group with an appropriate expiration date.
2021-07-27
Daniel met with Isaac to discuss database questions. Topics from both of us: Co-ops next term- we'll have one working on Inventory, and one working on SAT updates plus a few projects Isaac identifies.
- the team of Bahaa, Rona, and Dhruv is going really well. Code is looking good, we're squashing bugs quickly.
- Yes, auto-import of course sections will be ready. There will be sub-groups automatically generated, and Clayton can simply look up membership in the different sub-groups.
- Isaac has draft code for a group auto-generator
- Isaac can start working on this next week, with a fully spec'd sample so that we can demo it for users on Friday. Daniel will book a meeting for Friday the 6th.
- Isaac has been meeting with HR and has upcoming meetings to get very useful import data related to jobs. So eventually it will be trivial to set up auto-generated groups for "is employed in Computer Science"
- HRID, userid, all jobs user has/had. "classification fields" - job titles, family of jobs, supervisory structure / department.
- Isaac confirms our database update is going well, work with Nathan.
- Isaac is soon going to be able to import foreign schema directly from Oracle and eliminate a lot of manual import code.
- Daniel to organize this as a separate VM, in order to make sure we can deploy in August
- React/flask app philosophy of "exactly these package version numbers"
- a later (1-2 terms) goal of determining what's needed to put it on the 20.04 webserver cluster
- likely the biggest remaining ? for "how will we deploy in August"
- We both have the question: what users? Course accounts and ... ?
- What of these can't be imported to watiam? Why- just the amount of time, IST problems, other roadblocks?
- Isaac wonders about the campus "in-use list" which at one time informed IST about account IDs that can't be used by watiam. At one point they were reported from machines across campus.
- Structurally, Isaac suggests watiam should include accounts under the authority "because odyssey wants them there" in addition to "because HR/Quest wants them there". Would be nice!
- Could we manually add records to odyssey's identity management layer and manually maintain them? That sounds not very easy to maintain.
- Can the issue be handled by a flat-file "grandfathered accounts" list that simply contained account names and groups they should be in? So far this seems the most viable short-term solution for Aug 2021.
- Daniel will ask Dave and Adrian for details on lists of accounts
- Daniel to point Isaac at the up-to-date current questions, as the best way to approach these.
2021-07-30
Daniel, Dave, Clayton, Adrian to discuss SAT/Infrastructure. Agenda: Dave's question of "timeline for when we'll be done with /software/accounts-master/data/sponsors". Parenthetically: Work yesterday by Clayton in /RT#1167944: NEXUS account cs-mbx-cs-recru (which controls OWA access for cs-recruiting@uwaterloo.ca) is controlled by Sponsorship of computing resource "cs-mbx-cs-recru". Which does show up already in the new account system's imported data!- Clayton says this sort of thing will be a lot of the app usage: putting people in groups. Yes!
- Upshot: parts need rewriting before decommissioning accounts-master/xhier. Not any of these parts are requred before deploying the new system for controling access to resources.
- "removing" accounts is better described as "expiring" - which is a standalone daily process currently handled under accounts-master.
- it has rules for grace periods.
- accounts creation is handled automatically by Clayton's system after LDIF creation. It does not depend on the old accounts system to kick off creation. Though Adrian has questions on how it should create homedirs.
- currently queries the old idregistry system. That could be converted to Isaac's new database now.
- student region accounts currently using OAT.
- homedir assignment comes from the regional xhier masters. Hasn't been converted and Dave considers this a separate project for later (using a different database). OK.
- Other pieces? We didn't identify any for CS. This suggests we can introduce the new system for sponsorship maintenance and querying, and separately decommission accounts-master and friends which supply automatic processes (idregistry, expiration, homedirs).
- with the caution that expiration requires accounts-master data, so either we need to keep those files updated, or be OK with expired accounts lingering with no access.
- email alias sponsorship? deprecated and unlikely to be implemented if we're handing incoming email management to IST. OK.
- deployment on a separate webserver? Dave notes he's standing up an internal "www.cscf" webserver. But Daniel wants a guaranteed set of required packages, so better to use a separate VM. Dave says ask Anthony.
- Daniel to follow up with Isaac. This is unlikely to be completely solved in August, or until we can get a clear picture of what we need and how to provide it.
- Adrian notes there are some account names which IST would balk at creating in watiam, such as superuser,...
- potential short-term solutions:
- keep running accounts-master to handle "grandfathered" accounts.
- if the accounts only exist with standard resource sponsorship (nearly all in student region), could Clayton's scripts just accept a grandfathered accounts list, stored in a text file?
- Adrian asks if any grandfathered list would gracefully handle accounts that were then created in watiam.
- long term options: consideration of changing the app's use of unique person_ids so some do not come from watiam?
2021-08-04
Demo. Discovered issues on the fly. Will have another demo.- Robyn to supply a list of workflow items we should go through in the UI. (Lawrence suggests one item is "A new faculty member arrives.")
- Region names are currently confusing. Can we change these? Clayton says yes, his scripts can work with whatever we supply him.
- Questions about whether a SAT group has to have sponsorship.
- In the old system, it is assumed (but not enforced) that a "class" has a single sponsor. Adrian tested that a class can actually have more than one sponsor, though it warns about it.
- A difference in the new system is that a SAT group can be used for more than just sponsorship. It is possible for a SAT group to not be sponsored. And a SAT group can grant resources that have different sponsors.
- This leads to questions about how billing works for MFCF. Daniel can walk through this with Robyn... likely with assistance of a chart (to be made).
- Person data doesn't include HR. Can we tell who are grad students? To be addressed.
- Concern expressed about no batch update. To be addressed. The SQL API supports running a batch addition of members to a group, and Daniel/Isaac/Clayton can look at this further.
- Front page: capitalize Unix
2021-08-06
Meeting to discuss SAT automatic groups with Daniel, Isaac, Dave, Clayton, Adrian Agenda:- Demo of automatic groups for courses including sub-groups for sections.
- Discussion of what other components are needed for INF
- re-loading SAT schema into the dev database
- prepping a set of sample course groups for Clayton to experiment on (format examples:
cs241-1219-students, cs241-1219-tas)
- including every position a person is holding, such as csk will include both Prof and Director for Infrastructure.
- Isaac has been having meetings with HR and AD Computing; have signed agreements; the implementers are aiming for Sept.1
- When this is ready, it will be easy to supply groups for "staff within the faculty". Until then, it's manual updates.
- Adding a person to a course before Quest is updated: There are two approaches. Right now: add them to a manually updated group for the course. "Soon:" odyssey will have the concept of provisional class membership, which odyssey will feed into SAT just as if they are regular members. The updates will be done by course staff in odyssey. Course staff will have access to a screen for the specially added people.
- Batch additions to groups: we can handle batches by calling the stored procedures to add people to groups. This can also be done by Clayton. The API can support a command-line script to do this, though nobody has written that yet.
- Grad TAs? already part of odyssey group dump
- Sessionals? they are just instructors teaching a course; they are therefore already in odyssey; and therefore already in SAT groups as instructors.
- ISAs? can currently be recorded in odyssey; nobody has been doing it there, though. We can ask course staff to start. Isaac noted another feature that would be helped by that (Daniel didn't catch what that involves). Unclear whether this is part of this project's scope; Daniel to follow up with Isaac.
- "All Math students?" - we have students' plan/program, so we can make a group for this.
- Isaac has requested data including "all future appointments we should know about"; the implemeneters are digging into the hiring process. They wanted to know "how far in the approval pipeline do we want?" - Isaac thinks it should be when the offer letter has been accepted.
- This will be very useful for machine deployment and room allocation!
- Dave suggests an incremental process. For example, removing old accounts would still be done with the xhier package. Clayton's code already uses odyssey data to set groups; how much can we switch over to SAT in two weeks? Let's see.
- Daniel to update the master ticket with current incremental progress, since that's a bit out of date.
- Isaac suggests we use the basic definitions to grant privileges broadly for now. "all instructors who have taught in the previous n terms" could get access, leaving aside special sponsorship. When we have HR data, "If CS faculty member, always get access."
- Daniel to schedule a meeting in two weeks (Thursday the 19?) to revisit where we are at. (Possibly for entire SAT project group?)
- Daniel to schedule another demo, probably for early in that week.
2021-08-18
UI Demo
Meeting with Daniel, Dave, Adrian, Clayton, Isaac, Robyn, Lori S, Rona, Bahaa, and Dhruv. (Regrets from Lawrence, on vacation). Demo covered the following scenarios: 1) "Adding a new faculty member"- The process of creating their groups, and creating their sponsorships, is straightforward but likely needs a checklist to be sure of what to do in what order.
- At a later date when we know what can be done by assumption, we can turn this into a template. For example: do we need the group and billcode names to follow the old formats, or can we just name the billcodes "Professor Name, Research" and "Professor Name, Teaching"? To be discussed later.
- add the student ID to the appropriate group.
- add the student ID to the appropriate group. (They have a UW userid, and that is all we need).
- make a watiam ID and add them to the appropriate group.
- requires simple SQL queries, and isn't currently supported in the UI.
Meeting on additions to database schema
Daniel and Isaac met to discuss the additions we've written to make the app run. Isaac has a set of strong cautions that edits are not meant to rewrite history such as editing the quota on a resource suggesting that as of the start-date that resource had the new quota. Whereas the current code is relying on looking at the history log to see when the values were set. Isaac expects resource "edits" to actually be setting an end-date on the old resource and adding a clone with today's date and the edited values. This may be encapsulated in the stored functions our co-ops are currently using for edits. Isaac will look at this, along with the other code we've written. We should add functions for group_member_insert_manual (and delete, and edit) which includes logging. Because the existing group_member_insert is also used for automatic and odyssey imported group inserts, which shouldn't be logged because they will be thousands of lines on automatic group recalculations. There were other pieces discussed, and may be further discussed and noted later.Meeting with dev co-ops
Daniel met with the three co-ops and we made a master list of issues remaining; the co-ops have proceeded with tackling the most important ones. All three co-ops have accepted Daniel's offer to pay them for an extra week of work, ending Friday the 27th instead of Friday the 20th.2021-10-21
Since the start of term in September:- Daniel has set up a VM for sat.cs.uwaterloo.ca - currently needing assistance from Devon to make ADFS work properly.
- Daniel has been working with dev co-op Abhi Ardeshana to update the stored procedures, and we are working toward applying stored procedures on the dev database.
- Isaac has been working on a new dev database on Postgres 14 with a standardized install/import script to facilitate quick dev instances /RT#1000656
- What does it mean to edit quota resources? Isaac suggests that it's only that we can edit quota and everything else is a delete and create.
- However, the UI allows edits of all the properties, as a user-function.
- Daniel suggests we support this by having edit functions that allow all of the edits as implemented in the UI; the edit functions will do a delete then create.
- Isaac notes a deficiency in his edit implementation for future edits.
- He will re-implement future edits to resources- to delete old future, and add new.
- should log a delete and add. not just an edit which would report the new value. We need to also report the old value.
- different from what we have implemented, which was to record an edit; Daniel to note that in ticket.
- Monday: Isaac will put all stuff he's done relating to logging, on the new server.
- mc-3015-postgres-2004 - root from linux.cscf
- Daniel to check if Abhi has access
- Isaac to import his stuff already finished
- Then Abhi and Daniel can run our imports and test with the app and fix any issues
- Isaac will merge our functions into his import scripts
- Isaac's already written group_member_manual_insert and delete
- Abhi should rewrite group_member_edit as per RT#1120910
- noting an update to that ticket- I had said "except if the start date was also in the future"- group_member_insert_future does the delete automatically (UPDATE / INSERT = UPSERT)
2022-02-02
Demo with Research Support Group. Person page: Lori would like inventory link to include authorized user, plus loans.- inventory should update authorized user
- additionally, search for user should include all historical. he suggests "append not overwrite" to loans (that's a bigger change than I'd like to implement)
- Review data with Clayton and Adrian; what can we simply not import? Can we merge regions no longer critically separate?
- currently out-of-scope because adding time-of-day adds complexity throughout; but:
- would it be helpful to authorize users here, and book them elsewhere?
- to follow up with Lori.
- putting room near the top of page. does it need its own section?
- can we pull room from watiam/phone?
- Outlook/Office365 reports on our office; Lori says this is GAL (Global Address List) data - https://docs.microsoft.com/en-us/exchange/email-addresses-and-address-books/address-lists/address-lists?view=exchserver-2019
- which doesn't include grad students at this point; and doesn't include some staff/faculty.
- can we request that people update the authoratitve sources if they are incorrect?
- Outlook/Office365 reports on our office; Lori says this is GAL (Global Address List) data - https://docs.microsoft.com/en-us/exchange/email-addresses-and-address-books/address-lists/address-lists?view=exchserver-2019
- we don't want to make people update multiple sources; and not update local data that's better updated elsewhere.
- can we pull room from watiam/phone?
- move inventory/RTs lower in the page.
- most critical: details about grad student/staff/faculty and room.
- rename "RT" section to "service tickets" and include RT & Jira if possible.
- "Appointment": what is this? A: may be filled in with Job Appointments eg., Faculty service positions. Low priority at present.
- Lawrence: danger of user-entered data in non-standard formatting; difficulty of finding things in the old db.
- let's standardise policies. such as always use userid for group names, not "CSbd001"
- billing code - could we standardize on naming a default subscription code?
- since groups aren't necessarily separated for regions, the current naming convention which includes regions on import data should be reconsidered. (could we import into computed groups?)
- (for a faculty member, https://cs.uwaterloo.ca/cscf/research/sub/user.php?account=browndg shows relations in the upper-right side)
- is there a default subscription code?
- could subscription codes become groups, or other relations? For further discussion.
- for new grad students, they have no subscription code.
- can we link from supervisor name to their profile page?
- easy to change watcard photos by visiting the office.
- Daniel to follow up with Byron about suggestions on process (suggested by browndg)
- Daniel to follow up with Barb Daly. What can the app access, cheaply?
- someone comes to our offices; we will look up their userid and subscription code before making a ticket.
- could we press a button to have a new ticket populated with that information?
- new incoming grad student needs hardware.
- Lawrence starts from a list and creates a batch of tickets for action.
- need new system since Lawrence leaving?
- comes from grad office - inconsistent. student number (.1 sometimes)
- that data is not in quest.
- Lawrence says we should only need "userid" in order to create sponsor, plus default billcode, plus default group.
- yes, they should have a group of their own, even if resources will be managed for their research group.
- when they are first known to us, we will be assigning them equipment without knowing their full details.
- so there may be details changing, eg. moving users to a broader "group" when we learn their full details.
- would we want to kick off creating ticket(s) for new faculty? To consider.
2022-02-18
Meeting with Daniel and Isaac to discuss data imports. data tour - $ psql -h mc-3015-postgres-2004 -p 5505 odyssey (is my instance)- 2600 groups (1029-cs240-students = CS 240 Fall 2002 students)
- will trim expired groups, once he has deletion process working.
- update is accomplished by: select import_update_groups ();
- uses views named import_odyssey_* import_odyssey_groups_to_create import_odyssey_group_member_exports import_odyssey_groups - is what looks up master list of groups from courses
- list of courses is defined by the "cs classlist table in odyssey" * involving _instruct.teaching_admin?
- uses views named import_odyssey_* import_odyssey_groups_to_create import_odyssey_group_member_exports import_odyssey_groups - is what looks up master list of groups from courses
- the expiry data for terms will be when the update is run
- at the outset, it won't have accurate historic dates
- would be historic over time
- clayton: simple scripts! mostly SQL queries.
- no choice of exploits;
- given names - including backtick
- many cases will involve setting up separate admin units - essentially separate course instances.
- "topics courses" split by instructor already; new ones will need splitting by Isaac; either once or every term (by a flag).
- already used for exam-scheduling form ("is it usually or just this term?")
- q about grads versus undergrads? split by course (offering, then split by course/course-label)
- D to look up ticket, and follow up.
- Isaac to work on deletion; and restrict results to the groups we need.
- D to test out calculated groups in practice? the graphics lab?
- try an automatic group consisting of manual and imported groups
- at the level below quest import; and below the quest lookups that advisors do.
- so it's not a case for calculated groups. we will have to find out what uses they have.
- provisional memberships can include cases such as visitors without watiam, such as:
- highschoolers: can make an admin unit not fed from quest, we're ready to accept this kind of addon now.
- all people in certain plans and all people in certain courses. (outliers may want to disappear faster?)
- will need groups for all above inputs. - not done yet.
- calculated group for all people who should have an account: yes, we should have this.
- including manual groups, presumably.
- Isaac notes that he understands student's records better: can find: status: temporarily gone, reason LOA (leave of absence); return from leave of absence. discontinued. completed.
- much better data than "they aren't registered this term"
- deletion should be a process with many steps, many months.
- could be "send email to everyone who was a current student, ending n terms ago"
- "actually delete accounts for everyone who was a current student ending n+1 terms ago"
- D to meet with Clayton to find out what he needs.
- Isaac working first on "deletions" (deactivations); then improving groups; then plan-groups
- Daniel:
- find additional questions
- schedule meeting with Clayton to look at groups and code
- tell Lawrence if we're demoing, after talk with Clayton
2022-02-23
Isaac and Daniel met for a progress update.- As discussed last week, Isaac has odyssey group imports partly working, and populated in Daniel's new dev database. Isaac is currently working on odyssey group deactivations, and other group improvements.
- Daniel has set up a meeting with Clayton to answer his most pressing question, access to section ids; and if time allows, to review how he can use our queries.
- CS courses that have large numbers of students.
- netgroup limit 1700
- Precedent: upper-level courses needing different resources depending on section.
- Isaac asks: are these instances of different instructors doing it different ways? if so, already have odyssey breakdowns such as CS499(smith) and CS499(jones)
- or are they "same instructor and different resources"? Clayton says perhaps, but doesn't know of any.
- Not that Clayton's ever seen; although there are occasionally special unixgroups created by Adrian
- not used by "old classlist files" as supplied by Registrar
- new classlist is much more flexible, and is implemented within odyssey database.
- a course staff member can click a button in odyssey to tell it to create divisions.
- which, when Isaac implements it, will create separate SAT groups.
- course staff. "we care who your tutorial instructor is" vs "tutorial section" vs a variety of other section types.
- there are many kinds of sections we could use, but the question is which one would be important.
- Isaac's assertion is that the course instructors and staff know what are the important divisions, and are already doing this.
- The course may need to be split differently, by Isaac, either per-term or permanently (see just above, 2022-02-18 "topics courses" split by instructor already)
2022-03-01
Clayton, Isaac, and Daniel met to look at SQL queries. Key points:- Clayton confirms he has access to the new dev postgres Isaac set up for Daniel; via
psql -h mc-3015-postgres-2004 -d odyssey -p 5505 - We've given Clayton some sample queries to look at:
- to report all current SAT groups:
select * from _math_computing.group_group_current; - to report all current members of current SAT groups:
set search_path to _math_computing,_identity; select * from group_group_current NATURAL JOIN group_member_current NATURAL JOIN person_identity_complete; - the previous query but only reporting group_name and group member userid:
select group_name, userid from group_group_current NATURAL JOIN group_member_current NATURAL JOIN person_identity_complete;
- to report all current SAT groups:
- we discussed how Clayton uses the SAT group data- for the most part, course data only relies on the above group_name and group member userids.
- additionally, there is manual and automatic sponsorship of resources; those will require importing data from the old system that we haven't completed yet.
- SAT groups = old-system classes = AD netgroups
- SAT Unixgroups = AD security groups
- Clayton's "gids" are equivalent to getent group, not AD groups.
- SAT imported groups - defined outside of SAT, it's a data import, such as from Quest. eg., "everyone in CS241"
- SAT calcuated group - groupA is groupB union with groupC (or groupB intersected with groupC)
- For Clayton: what group name format will allow you to take the SAT group name verbatim and have consistent naming between your sub-systems rather than "SAT imported Group named Xxxxxx becomes netgroup named Yyyyyy"
- Probably
scs-cs135-stdandscs-cs135-adminfor students and admins respectively. Clayton to confirm this is what he'd like. - Clayton nests those into a netgroup for
scs-cs135
- Probably
- For Clayton: is it ok to automatically make AD groups for all SAT groups? That would simplify his automation. He currently makes >200. There will likely be >2000 SAT groups.
- optionally, some SAT groups will become security groups if they are sponsored to include SAT unixgroups.
- What is missing from the data for Clayton to completely perform accounts actions?
- we can re-visit after Clayton has done script updates to test imports using the above.
- we know we need to set up the sponsorships of additional resources; either manually, or a semi-automated import from the old system.
- Daniel to do a draft semi-automated import.
- There are process decisions, such as "when are accounts generated or deleted?" - to be driven by what INF needs, with recommendations from Isaac/Daniel about improvements.
- We can easily support "select all userids for someone whose most recent class (SAT group) was at least a year ago" or, if desired, even "select everyone who Quest thinks is finished."
- For further discussion: should naming of all SAT groups should be constrained to have that format?
- Argument for: in general, manual group names need some kind of discipline.
- Argument against: the use of SAT groups is broader than netgroups/AD groups/security groups.
- It makes sense that if they have that format, they can be selected by Clayton to become netgroups; and if they don't, they are not.
2022-03-21
Demo with Diana concerning rooms and desks.- She hopes to have this in place before Fall 2022 grad student desk assignments.
- She says very useful in our current implementation.
- She thinks they will use the room-group associations- they will prefer to put people into rooms for the same group, but will put them where space is available.
- Yes, SAT will display phone-numbers. But we won't update them; that's via IST.
- Yes, we will display and edit room and desk. But we can't update IST's room locations found in watiam.
- side-note: her group is also responsible for updating WCMS room and phone-number info; which is a separate batch of updates for them as well, that aren't always done.
- They will need: rooms and desks; and current desk occupants.
- They would like: group associations (but that can be added later).
- Hopefully we can get access to Grad Office data eventually; she understands it won't be there at the outset.
- She described what they had in a peoplesoft management system at Western which offered canned queries and downloads.
- The actual need is to view all room and desk data on one screen, rather than split up by rooms as it currently is.
- In discussion with the co-ops, we will work on a fairly straightforward option, which is a desk view which is not restricted to one room; otherwise it would be very close to the "desk" page.
- I've tested copy-and-pasting into excel; the tables from both Rooms and Room will paste into excel (except for the header; I'm not sure there's an easy way to add that).
- Diana says they would like to know room, desk, occupant, and optionally phone number (which isn't critical). We can also display desk notes.
- There should be rows for empty desks; and there should be full filtering capabilities.
- The above could be linked from the "rooms" page, perhaps via a button labeled "Spreadsheet View" right-aligned in the same row as "Add new room"
2022-04-25
Demo with Diana and Greg Q: are Desk notes editable/deletable? What if it was for the person in the desk?- discussion shows that Greg occasionally will want per-person notes. Diana suggests potentially these would include: accessibility needs (standup desk); X doesn't get along with Y...
- So those could be person notes, possibly for the person page, but it would need privacy to certain users.
- Given the sensitivity, Daniel recommends keeping this out of the app, in a private file shared between Greg and Diana.
- on sat.cs (but not Sehaj's dev), edits to a room dates didn't save. Sehaj's re-test found a small bug, to be addressed.
- Diana says Crysp currently has 25 seats. They're setting an end-date for DC3333 of 2022-12-21, and then a start-date for a new DC3333 of something like 2023-03-01 with 45 seats.
- SCG and ALG will be combined into one lab, this Fall.
- I agreed to work with them to batch-enter the needed data (so we know how this works.)
- This indicates that the stored procedure Sehaj wrote is going to be used beyond the initial imports. Or we'll need batch room updates in the UI, at some point.
- use-case is initially adding incoming grads and visitors.
- person page includes grad program already
- grad office has enhanced info that we hope to access eventually.
- Potentially pulled from HR/Workday?
- There may be visitors without watiam, though likely few. If so, we'd have to import them into odyssey. (with an undefined process but we need to figure that out for accounts.)
- The UI already has the "Appointments" table, though we haven't looked at that at all recently.
- Who would update this? HR -> workday? Tracy? Tracy sending a spreadsheet into the system?
- xls sheet saved without file extension
- downloads (excel and .csv) should split the start and end dates.
2022-08-30
Demoed to CSCF, focusing on ExpertiseDatabase to fulfil CS Director's request for an enhancement to our public website- Uses basic SAT building blocks: "Groups" = regular CS faculty members plus CS Cross-Appointments minus CS Faculty No Profiles
- Adds a simple php/js front-end to search for people or groups.
- Dave requested importing "who does what" list. Similarity?... I said different but similar schema; we can discuss.
2022-10-27
Status update:- Database design issues have blocked deployment (see /RT#1170750) - now unblocked.
- Waiting for followup from Clayton / INF concerning Accounts/Sponsorship (see RT#910469)
- Meanwhile, Daniel is working to deploy the ExpertiseDatabase and Rooms portions of the app this term, which will then provide a solid basis for testing the Accounts/Sponsorship portions of the app.
2022-10-27 Roadmap
- Oct 28: 1-on-1: document what we need broadly in order to accomplish these milestones (in this roadmap). - Nov 10: 1-on-1: complete copy of SQL on prod database, with documented install/reinstall process - requires (early) pull of Isaac's current schema updates to prod odyssey - including list of tests of data and database to ensure the copy from dev to prod is complete and accurate - including new schemas for _people and _expertise; reviewed with Isaac - Nov 16: we have prod DB set up and dev app working sufficiently to onboard Joe Petrik - after we have confirmed initial data with Joe, deploy the expertise website - (or, by his choice, don't deploy it until after he's finished updates including renaming their profile paths) - CSCF can use the app to look up grad students and other visitors - Nov 24: 1-on-1: we have prod DB set up and dev app working sufficiently to onboard Greg - possibly including up-to-date data from the current rooms database; we have a dump and restore script to make it quick - Dec 7: deliver 20-minute WatITis talk - Dec 8: 1-on-1: discuss feedback from Joe, Greg, WatITis, RSG users, etc; discuss plan for W2023 and onward - plans include: moving dev app onto prod webserver; meeting with INF for documented spec to roll out accounts/sponsorship; - v1.1 plans: access levels for different users, other needs identified by end-users - Dec 16: app is deployed and documented for users - CSCF knows how to look people up, and potentially add people to groups - includes sketched-in documentation for accounts/sponsorship so adding details won't require a complete doc rewrite
2022-10-28
Discussion between Dave/Clayton/Daniel about current status.- Daniel has a 7-week timeline to deploy time-critical portions of SAT this term, which includes necessary pieces for ExpertiseDatabase (project sponsor Raouf Boutaba) and Rooms (for Greg McTavish), along with (non-time-critical) general CSCF access for client information lookups.
- Early in this process will be a prod database deployment, which will provide a solid basis for testing and deploying the Accounts/Sponsorship portions of the app.
- Discussed definitions of terms in SAT so we're on the same page.
- Discussed the questions asked of Clayton in /RT#910469.
- Yes, group name examples "scs-cs135-std and scs-cs135-admin" sound fine to Clayton.
- Clayton talked with Isaac about the limited amount of development data visible, some time after March
- Clayton reported that in course membership, all roles were either "student" or "admin" - he requested more types from Isaac but that request didn't make it into a ticket.
- Clayton will look into the role definitions and document for us what he needs.
- Yes, OK to make additional AD groups for all SAT groups; and Clayton can test to make sure 2000+ groups will be OK.
- What is missing from the data for Clayton? Before that, he needs to do tests on imports.
- Before that, we need the populated automatic groups. And before that, Daniel and Isaac need to set up the production database.
- Daniel to ask Isaac for help populating this.
- We're on the same page that SAT groups staring with netg_ will be selected in Clayton's tools to become a netgroup.
- A feature request to have netgroup resources which can be associated with groups (parallel to the "login" and "mail alias" resources which already exist), to have the other elements of the netgroup triplet.
- Dave documented this as:
the concept of group "types" type={AD security, RFC2307 group, RFC2307 netgroup, ...}
- Dave documented this as:
- A feature request to have netgroup resources which can be associated with groups (parallel to the "login" and "mail alias" resources which already exist), to have the other elements of the netgroup triplet.
- Yes, group name examples "scs-cs135-std and scs-cs135-admin" sound fine to Clayton.
2022-11-02
Daniel met with Isaac; we have a process to follow for schema updates.- this morning Isaac ran the installer script on :5501 ("Demo database") - it appears to have run cleanly
- Daniel will put update changes from :5505 (Daniel's dev database) into a .sql, and run it on :5501
- tomorrow Isaac will reload odyssey data from production into :5501, and re-run installer script
- (timing unspecified; soon) Isaac will install the cron to daily update computed groups from "future" tables
- Daniel will test the app on :5501, including computed groups with future start-dates
- We will coordinate with Clayton because his SQL needs updating: _math_computing to _math_computing_old
- Isaac will rename the old _math_computing to _math_computing_old
- we will reproduce the import on postgres.odyssey
- Daniel will shift the app to use postgres.odyssey.
2022-11-24
Discussion between Daniel and Joe to onboard Joe to do Expertise edits. Notes in RT#1137425- Daniel sent Joe a spreadsheet for data-entry, and a list of WCMS Contact Pages that need cleanup.
- Joe will do data-cleanup and will come back to Daniel with questions and comments.
- Joe hopes to do data entry in Nov/Dec, but this is on a long list of priority work.
2022-12-14
- Tour with Greg on SAT rooms: see also /RT#1211999. Agenda
- look at the data in the app
- All rooms and occupants as of April 2022, plus what he's given me last week.
- I've filled nearly all of Lab tab
- eg., SWAG with lots of only-first-names he was worried about- we succeeded automatically identifying 14/17 in DC2555 and 7/15 in DC2544
- walk through a few situations of updates
- manually update a few from the '2000' tab
- Q&A
- Daniel to take away feature requests or issues we identify
- look at the data in the app
- Data for Daniel to fix:
- TODO All lab desks starting with alpha characters are actually lab rooms.
- eg., 2554 desks B1, B2, B3, C4, C5, C6 are actually two rooms, 2554B and 2554C, each with three desks.
- can I fix that in batch? Or there will be a lot for Greg to do manually.
- Necessary? the user could figure out what it means as-is, but it is more correct and less surprising to users if it's fixed.
- Greg will send me the other spreadsheet for staff, with updates since April. I haven't imported updates in the admin wing.
- TODO I will let him know what I can easily import, and what he has to do manually
- TODO All lab desks starting with alpha characters are actually lab rooms.
- Tour.
- Looking up "Wei Hu" - too many matches to be helpful.
- could we sort results according to usefulness?
- could we limit name search results to math faculty? This will be a big improvement; already in Daniel's queue.
- I noted that reviewing pages may be clunky if there are more than 10 results, since our default 10 results is small.
- Greg suggests default results 25 not 10
- spreadsheet view:
- finding unoccupied desks: obvious choice of "sort by occupant" puts "No Occupant" between M and O.
- "No Occupant" should be first.
- can we see Masters' or PhD status of the occupant on the spreadsheet view?
- He uses this while picking the more desirable desks for PhDs.
- I suggested recording desk note "Window seat" to describe those locations.
- I can look into adding that data, but it might be a while
- (also, what terse values to show for a person; "Mmath / PhD" and none if they aren't?)
- how do we find people who don't have seats?
- at present, use whatever data source Greg was supplied with, such as Grad Office incoming students sheets.
- in the future, there will be automated groups for odyssey-imported data.
- But SAT doesn't yet have a front-end way to display the location info for everyone in a SAT group.
- Greg will maintain a spreadsheet of external personal details,
- such as 'this person requires a standing desk'
- or 'person A cannot be in the same room as person B'.
- The above shouldn't be in SAT for confidentiality reasons.
- This spreadsheet can also include "working from home" for people who won't be assigned desks.
- what if someone shifts from Masters' to PhD? Can he find out if there are PhD offices available and figure out who to move there?
- PhD offices could be recorded in room groups; discussed below.
- when a person shifts programs, he doesn't necessarily hear from the Grad office.
- this case is low priority for him to update.
- his workflow: he will be updating to include January additions, and then he will go through and contact each student individually to verify they need a seat.
- discussed that after I do imports, hopefully he can do updates going forward (and give me feedback about frustrations).
- I showed him how to dump a report of all seats.
- of the 550 seats, 400 are grads.
- Report doesn't differentiate between grad/non-grads and grad/non-grad seats.
- we need to add appropriate SAT groups to the rooms, so he can report on grads.
- My initial suggestion: a "CS Desks" group containing these sub-groups:
- CS Lab
- CS Masters'
- CS PhD
- CS Visitor
- CS Staff
- but these aren't firm; he clusters PhDs together, but will put an appropriate Masters' in the room as well.
- and there are very few dedicated Visitor spaces
- I will consider other options and get back to him with ideas. Could be: replicating his current data:
- CS 2000
- CS 3000
- CS Lab
- CS Directory
- My initial suggestion: a "CS Desks" group containing these sub-groups:
- finding unoccupied desks: obvious choice of "sort by occupant" puts "No Occupant" between M and O.
- We dealt with DC2306, which is being renovated in January. All the spots are empty.
- So we deleted the room and created a new one with 36 desks.
- App Bugs to record:
- it did not show a green alert when a room was created with desks (/RT#1261139)
- room results: on the spreadsheet view, it doesn't show that the first iteration of DC2306 was deleted. (existing /RT#1221030)
- it did on the Rooms page: the old one displays as "DC2306 (ending 2022-12-14)"
- and adding a search-term of tomorrow's date, it only shows the new room.
- but the spreadsheet view, it does not indicate this (or remove the out-of-date desks)
- it did on the Rooms page: the old one displays as "DC2306 (ending 2022-12-14)"
- Discussed data questions.
- he will update SAT to add desks that were comments in the spreadsheet. eg., 2554 has 8+ unallocated open spaces.
- he can start updating both SAT and his spreadsheet, with January updates.
- discussed currently treating the spreadsheet as authoritative; we will work on making SAT authoratative instead.
- and he will bring me questions as they come up.
- I will check back with Greg about data-imports I can quickly do this week; and I'll check in some time in early/mid January about questions.
- Looking up "Wei Hu" - too many matches to be helpful.
2022-12-16
- Discussed with Isaac about using user-accounts and row-level privileges to handle SAT access privs. The goal is minimal additions that make it easy to limit access. This seems feasible. I can work on it once I have Accounts deployed (hopefully six months from now).
2023-01-16
Overall status:- Expertise: waiting for a meeting with Raouf to demo.
- Rooms: waiting for feedback from Greg
- Accounts: waiting for Clayton to make updates to CS systems; then pulling production accounts data into the system before switching over.
2023-05-30
Demo to MFCF (Lori S, Jim J, Robyn L); with Daniel A, Lori P, and Dave G. MFCF will need for the UI:- Sponsorship page should not only show billcodes; it should also have an option to additionally break down everything "within" those billcodes:
- Resources; SAT Groups (classes); group members; likely audit log
- to replicate "viewing everything about a sponsorship"
- many comments will be encoded in sub-groups by their names and descriptions
- they will definitely use the start and end dates for some sponsorships.
- MFCF doesn't have immediate time-pressure to go live soon, only pressure based on people still being available to do the conversions.
- At present there is no privilege separation and SAT is all one database (unlike Inventory).
- Daniel thinks we might be ready to work on privilege separation in the Fall.
- If MFCF wanted to load production data sooner than we implement the privilege separation, we will have to have standards for not stomping on each other's data.
- Daniel will re-import general-region sponsorships - such as SAT groups (classes) - in the next few weeks.
- Robyn will construct a fake sponsor definitions file to import into SAT.
- we could run that in CS's usual accounts-master postgres export.
- ideally, we would point the exporter at a dev database instead of production.
- Lori S. will schedule a followup meeting for further discussion (same invitees)
- Dave will schedule a followup meeting for Clayton and Daniel (&?) on the progress of the INF tools.
- Jim J will prep materials on the scripts he runs
- (Daniel asked a precursor question: if it's currently operating based on "class" names, can it instead simply do the same operations based on "SAT group" names?)
2023-08-17
- notes in /RT#1211999 on room occupant data-import and discussion with Greg, and bugs identified to fix while working on room imports.


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
2020-01-23-SAT-API-consumers-for-accounts.jpg | r1 | manage | 1543.2 K | 2020-01-28 - 12:08 | DanielAllen | white-board: how API will be used for CS accounts generation |
| |
IMG_7091_IMG_7092.jpg | r1 | manage | 2123.1 K | 2019-12-12 - 17:09 | DanielAllen | white-board: current accounts creation |
| |
IMG_7093.JPG | r1 | manage | 1574.9 K | 2019-12-12 - 17:09 | DanielAllen | white-board: current accounts creation |
| |
IMG_7094_IMG_7095.jpg | r1 | manage | 2467.9 K | 2019-12-12 - 17:09 | DanielAllen | white-board: current accounts creation |
| |
IMG_7096.JPG | r1 | manage | 1320.3 K | 2019-12-12 - 17:09 | DanielAllen | white-board: current accounts creation |
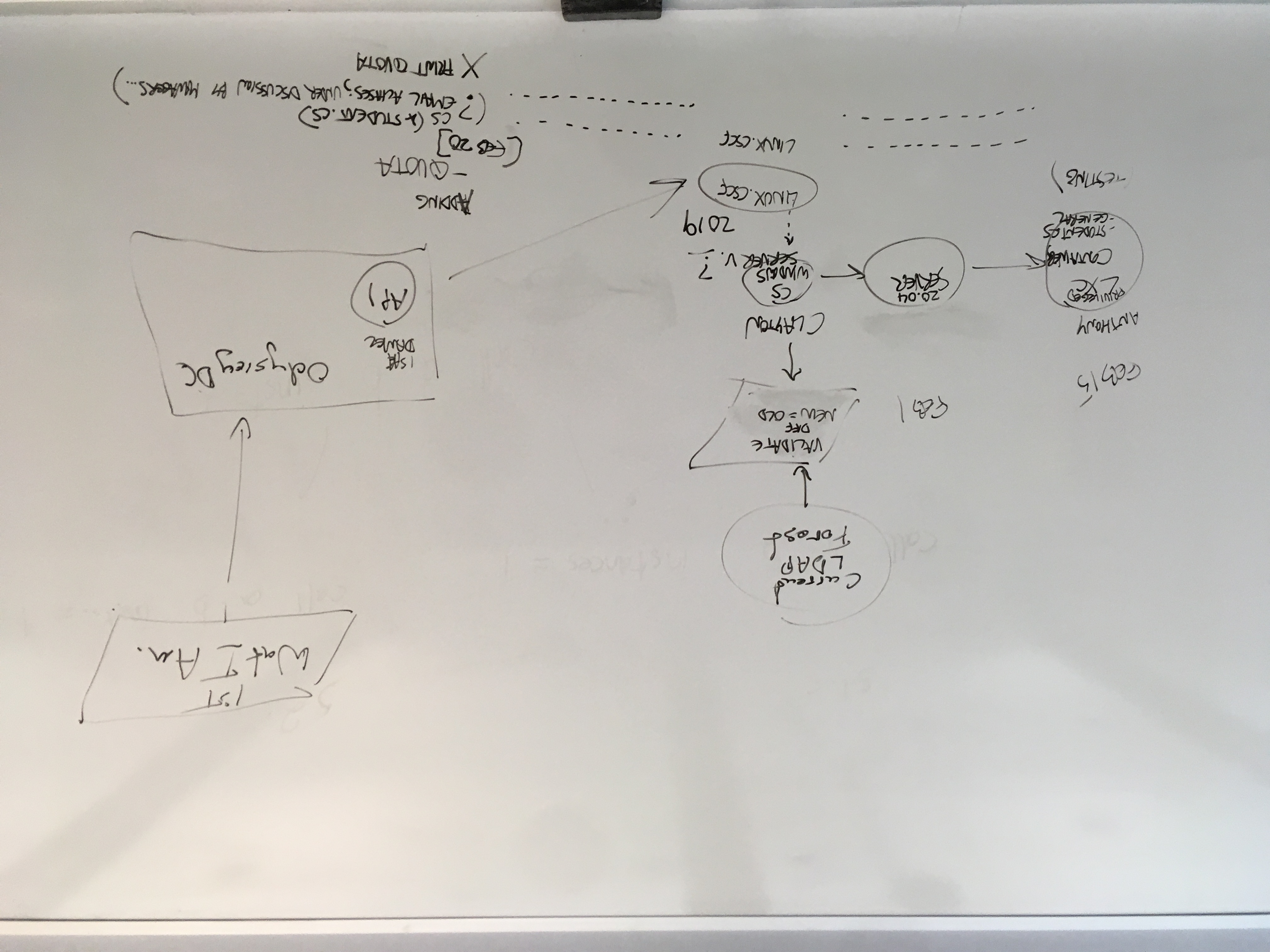{kind=link}
{kind=link}
{kind=link}
{kind=link}
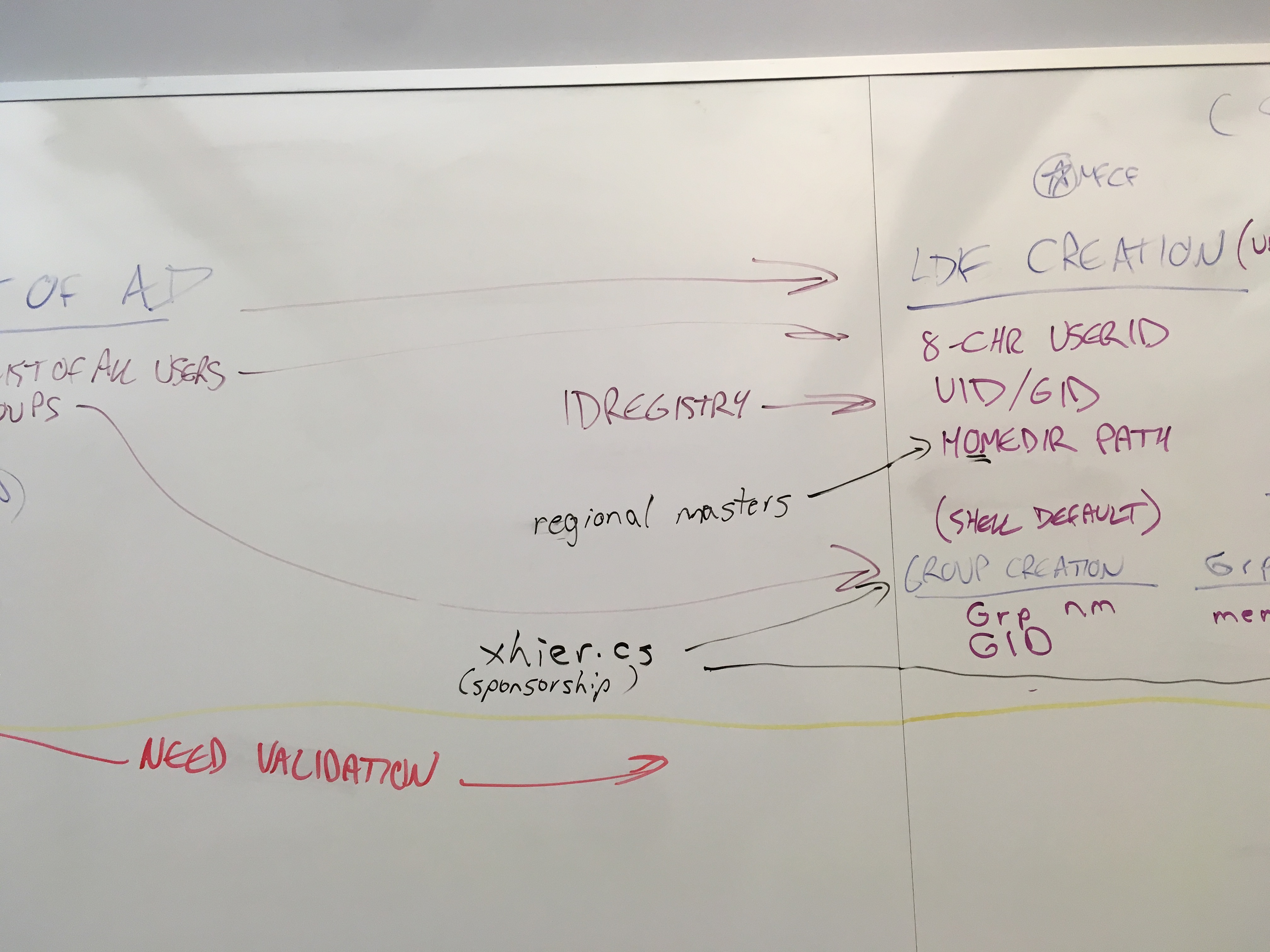{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Topic revision: r120 - 2023-09-11 - DanielAllen
Information in this area is meant for use by CSCF staff and is not official documentation, but anybody who is interested is welcome to use it if they find it useful.
- CF Web
- CF Web Home
- Changes
- Index
- Search
- Administration
- Communication
- Hardware
- HelpDeskGuide
- Infrastructure
- InternalProjects
- Linux
- MachineNotes
- Macintosh
- Management
- Networking
- Printing
- Research
- Security
- Software
- Solaris
- StaffStuff
- TaskGroups
- TermGoals
- Teaching
- UserSupport
- Vendors
- Windows
- XHier
- Other Webs
- My links
 |
|
Ideas, requests, problems regarding TWiki? Send feedback