
Older adults living with cognitive disabilities (such as Alzheimer's disease or other forms of dementia) have difficulty completing activities of daily living (ADLs). They forget the proper sequence of tasks that need to be completed, or they lose track of the steps that they have already completed. The current solution is to have a human caregiver assisting the patients at all times, who prompts them for tasks or reminds them of their situation. The dependence on a caregiver is difficult for the patient, and can lead to anger and helplessness, particularly for private ADLs such as using the washroom.
Here we present our real-time system for assist persons with dementia during handwashing. Assistance is given in the form of verbal and/or visual prompts, or through the enlistment of a human caregiver's help. The system uses only video inputs, and combines a Bayesian sequential estimation framework for tracking hands and towel, with a decision theoretic framework for computing policies of action -- specifically a partially observable Markov decision process (POMDP). A key element of the system is the ability to estimate and adapt to user states, such as awareness, responsiveness and overall dementia level.
This project is part of the COACH project.
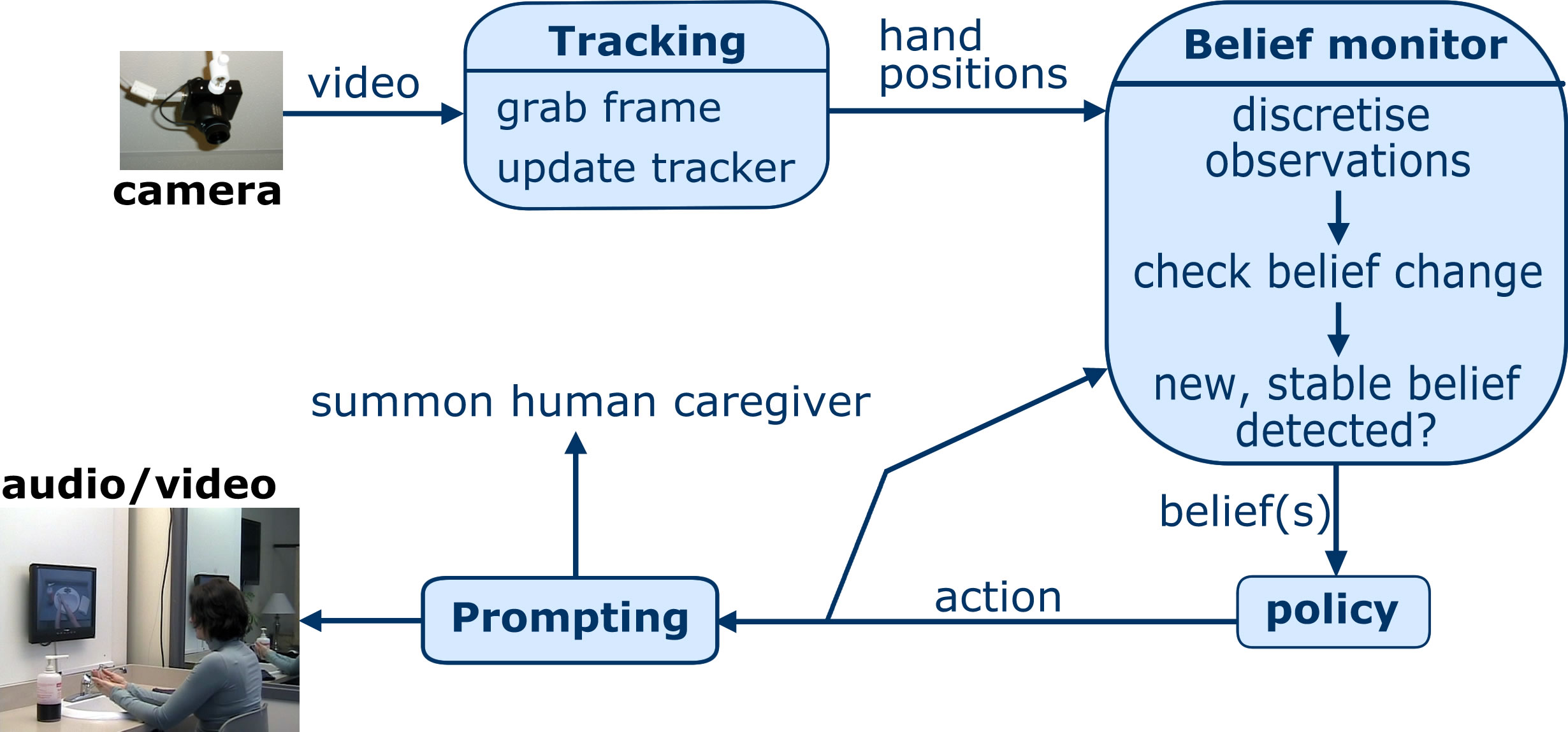
The overall system works as follows as shown above. Video is grabbed by an overhead Point Grey Research Dragonfly II IEEE-1394 camera, and fed to a hand and towel tracker. The tracker reports the positions of the hands and towel to a belief monitor that tries to estimate where in the task the user is currently: what have they managed to do so far, and what is their internal mental state. The belief about where the user's state is then passed to the policy. The policy maps belief states into actions: audio-visual prompts or calls for human assistance.
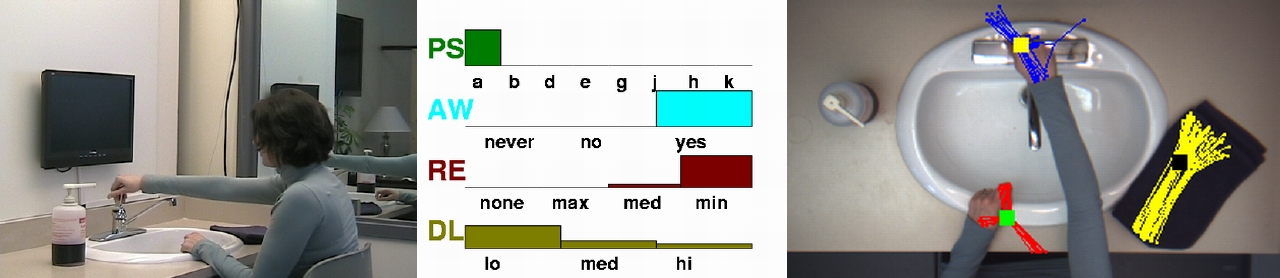
- On the left, you see video taken from an independent video camera showing the whole scene. This video is not used by the system.
- On the right, you see the video from the overhead camera
- In the middle, you see the belief state in the planstep (PS), the awareness (AW), the responsiveness (RE) and the overall dementia level (DL).
Scenario B actor trial - person needs some assistance, but is responsive to audio prompts.
Scenario C actor trial - person needs assistance for most steps, and is only responsive to video prompts. The system learns this after an initial attempt with audio prompts, and then switches to using video only.
More details can be found by reading the following papers:
- Aarti Malhotra, Jesse Hoey, Alexandra Konig and Sarel van Vuuren A study of elderly people's emotional understanding of prompts given by Virtual Humans. Proc. International Conference on Pervasive Computing Technologies for Healthcare, Cancun, Mexico, 2016 (bibtex)
- Aarti Malhotra, Lifei Yu, Tobias Schroeder and Jesse Hoey An exploratory study into the use of an emotionally aware cognitive assistant. University of Waterloo School of Computer Science Technical Report, CS-2014-15, August, 2014 (bibtex)
- Luyuan Lin, Stephen Czarnuch, Aarti Malhotra, Lifei Yu, Tobias Schroeder and Jesse Hoey Affectively Aligned Cognitive Assistance using Bayesian Affect Control Theory. Proc. of International Workconference on Ambient Assisted Living (IWAAL), Belfast, UK, 2014 (bibtex)
- Jesse Hoey, Craig Boutilier, Pascal Poupart, Patrick Olivier, Andrew Monk and Alex Mihailidis People, sensors, decisions: Customizable and adaptive technologies for assistance in healthcare. ACM Transactions on Interactive Intelligent Systems, 2, 4, New York, NY, December, 2012 (bibtex)
- Jesse Hoey, Pascal Poupart, Axel von Bertoldi, Tammy Craig, Craig Boutilier and Alex Mihailidis Automated Handwashing Assistance For Persons With Dementia Using Video and a Partially Observable Markov Decision Process. Computer Vision and Image Understanding (CVIU), 114, 5, May, 2010 (bibtex)
- Alex Mihailidis, Jennifer N. Boger, Marcelle Candido and Jesse Hoey The COACH prompting system to assist older adults with dementia through handwashing: An efficacy study. BMC Geriatrics, 8, 28, 2008 (bibtex)
- Jesse Hoey, Axel von Bertoldi, Pascal Poupart and Alex Mihailidis Assisting Persons with Dementia during Handwashing Using a Partially Observable Markov Decision Process. Proceedings of the International Conference on Vision Systems, Bielefeld, Germany, 2007 (bibtex)
- Christian Peters, Sven Wachsmuth and Jesse Hoey Learning to recognise behaviours of persons with dementia using multiple cues in an HMM-based approach. Proceedings of the ACM 2nd International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 2009 (bibtex)
- Jennifer N. Boger, Jesse Hoey, Pascal Poupart, Craig Boutilier, Geoff Fernie and Alex Mihailidis A Planning System Based on Markov Decision Processes to Guide People with Dementia Through Activities of Daily Living. IEEE Transactions on Information Technology in BioMedicine, 10, 2, 2006 (bibtex)
Details on the hand tracker can be found in the following paper, presented at BMVC 2006
- Jesse Hoey Tracking using Flocks of Features, with Application to Assisted Handwashing. Proceedings of British Machine Vision Conference, Edinburgh, Scotland, 2006 (bibtex)
A paper describing our work in validating the use of actors to simulate dementia appears in
- Jennifer N. Boger, Jesse Hoey, Kate Fenton, Tammy Craig and Alex Mihailidis Using actors to develop technologies for older adults with dementia: A pilot study. Gerontechnology, 9, 4, 2010 (bibtex)
- Applying it to other tasks, such as mobility (e.g. powered wheelchairs), emergency response (e.g. non-invasive community alarms), and other ADL in the washroom, such as toothbrushing or toileting. See the following paper for a general overview of these projects and how the same technology could be used.
- Jesse Hoey, Craig Boutilier, Pascal Poupart, Patrick Olivier, Andrew Monk and Alex Mihailidis People, sensors, decisions: Customizable and adaptive technologies for assistance in healthcare. ACM Transactions on Interactive Intelligent Systems, 2, 4, New York, NY, December, 2012 (bibtex)
- Jesse Hoey, Pascal Poupart, Craig Boutilier and Alex Mihailidis POMDP models for Assistive Technology. AAAI 2008 Fall Symposium on AI in Eldercare, 2005 (bibtex)
- Making the system adaptive over time, in both the short and long terms. This involves offline learning from data, and online learning. See the SNAP and DIY Smart Home projects.
- Exporting the system as a commercial device. Partners wishing to be involved should contact Jesse Hoey or Alex Mihailidis.