Peter van Beek
Cheriton School of Computer Science
University of Waterloo
Research: Computational photography
Many interesting computational problems arise in digital photography. Some of the problems involve the basic functionality of a camera such as automatic focusing, automatic white balancing, and automatic exposure. Other problems extend the capabilities of the camera such as high dynamic range (HDR) imaging and focus stacking. Our current research involves algorithms for automatic focusing, focus stacking, and white balancing. In passive autofocusing, a lens is focused using only the camera's optical system and an algorithm for controlling the lens. In focus stacking, multiple images—each taken at a different focus depth—are combined into a single image. The combined image has a greater depth of field (the nearest and farthest objects in the scene that are in focus) than the individual images. White balancing is a fundamental step in the image processing pipeline. The process involves estimating the chromaticity of the illuminant or light source and using the estimate to correct the image to remove any color cast. The goal of the research is to discover improved algorithms for these tasks using supervised machine learning techniques.
Project: Camera remote control software
Description
A camera remote control application whereby a Canon EOS camera is tethered to a computer via a USB cable and controlled by the software running on the computer. Our remote control application makes use of the Canon SDK (EDSDK Version 2.11) and can control and replicate the basic functionality of the camera such as setting the aperture, displaying the live preview stream, displaying a histogram and clipping preview, controlling the focus position of the lens, and capturing video. As well, there are extensions to the basic functionality such as exposure bracketing, focus bracketing, multi-shots at intervals, and panorama multishots.
Software
The source code and related files: README.txt, Src_v1.0.zip. The code runs only under Windows and requires the Canon Digital Camera SDK (EDSDK), only available from Canon (see the README).
Project: Focus measures
Citation
(PDF) Hashim Mir, Peter Xu, and Peter van Beek. An extensive empirical evaluation of focus measures for digital photography. Proceedings of IS&T/SPIE Electronic Imaging: Digital Photography X (Vol. 9023), San Francisco, February, 2014 (slides).
Abstract
Automatic focusing of a digital camera in live preview mode, where the camera's display screen is used as a viewfinder, is done through contrast detection. In focusing using contrast detection, a focus measure is used to map an image to a value that represents the degree of focus of the image. Many focus measures have been proposed and evaluated in the literature. However, previous studies on focus measures have either used a small number of benchmarks images in their evaluation, been directed at microscopy and not digital cameras, or have been based on ad hoc evaluation criteria. In this paper, we perform an extensive empirical evaluation of focus measures for digital photography and advocate using two standard statistical measures of performance, precision and recall, as evaluation criteria.
Software and data
Code and results for the evaluation of focus measures described in the paper: README.txt, focus_measures.zip

Figure 1. Focus measures of images at each of the 167 lens positions (50 mm lens) for an example scene using (a) the squared gradient focus measure, and (b) the Laplacian of Gaussian focus measure. The four vertical bars refer to the four images that have objects that are in maximal focus: (c) cup, (d) edge of desk, (e) window sill, (f) and fence in focus. On this benchmark, the squared gradient has precision 3/3 and recall 3/4, and the Laplacian of Gaussian has precision 4/4 and recall 4/4.
Project: Autofocusing algorithms, best focus
Citation
(PDF) Hashim Mir, Peter Xu, Rudi Chen, and Peter van Beek. An autofocus heuristic for digital cameras based on supervised machine learning. J. of Heuristics, 21(5):599-616, 2015.
Abstract
Digital cameras are equipped with passive autofocus mechanisms where a lens is focused using only the camera's optical system and an algorithm for controlling the lens. The speed and accuracy of the autofocus algorithm are crucial to user satisfaction. In this paper, we address the problems of identifying the global optimum and significant local optima (or peaks) when focusing an image. We show that supervised machine learning techniques can be used to construct a passive autofocus heuristic for these problems that out-performs an existing hand-crafted heuristic and other baseline methods. In our approach, training and test data were produced using an offline simulation on a suite of 25 benchmarks and correctly labeled in a semi-automated manner. A decision tree learning algorithm was then used to induce an autofocus heuristic from the data. The automatically constructed machine-learning-based (ml-based) heuristic was compared against a previously proposed hand-crafted heuristic for autofocusing and other baseline methods. In our experiments, the ml-based heuristic had improved speed—reducing the number of iterations needed to focus by 37.9% on average in common photography settings and 22.9% on average in a more difficult focus stacking setting—while maintaining accuracy.
Software and data
Code and labeled data sets for the supervised machine learning approach and evaluation described in the paper: README.txt, ml_autofocus.zip
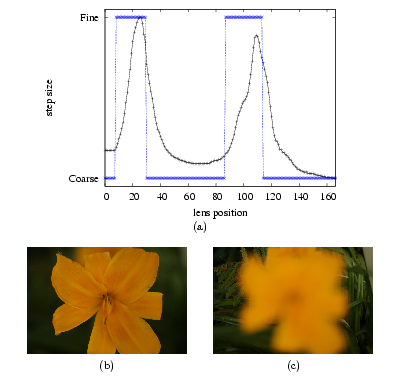
Figure 1. (a) Focus measures of images at each of the 167 lens positions for an example scene labeled with the best next step to take (a Fine step, or a Coarse step) when sweeping the lens from near to far (left to right in graph). The peaks in the focus measure correspond to two images that have objects that are in maximal focus: (b) flower in focus, and (c) fern and grasses in focus.
Project: Autofocusing algorithms, hill-climbing
Citation
(PDF) Rudi Chen and Peter van Beek. Improving the accuracy and low-light performance of contrast-based autofocus using supervised machine learning. Pattern Recognition Letters, 56:30-37, 2015.
Abstract
The passive autofocus mechanism is an essential feature of modern digital cameras and needs to be highly accurate to obtain quality images. In this paper, we address the problem of finding a lens position where the image is in focus. We show that supervised machine learning techniques can be used to construct heuristics for a hill-climbing approach for finding such positions that out-performs previously proposed approaches in accuracy and robustly handles scenes with multiple objects at different focus distances and low-light situations. We gather a suite of 32 benchmarks representative of common photography situations and label them in an automated manner. A decision tree learning algorithm is used to induce heuristics from the data and the heuristics are then integrated into a control algorithm. Our experimental evaluation shows improved accuracy over previous work from 91.5% to 98.5% in regular settings and from 70.3% to 94.0% in low-light.

Figure 1. State diagram illustrating the control algorithm. In the initial state, a prediction is made about the direction of a peak. The lens will take steps in that direction (possibly backtracking once) until a peak is found or the search fails.
Project: Focus stacking algorithms
Citation
(PDF) David Choi, Aliya Pazylbekova, Wuhan Zhou, and Peter van Beek. Improved image selection for focus stacking in digital photography. Proceedings of IEEE International Conference on Image Processing (ICIP-2017), Beijing, China, September, 2017
Abstract
Focus stacking, or all-in-focus imaging, is a technique for achieving larger depth of field in an image by fusing images acquired at different focusing distances. Minimizing the set of images to fuse, while ensuring that the resulting fused image is all-in-focus, is important in order to avoid long image acquisition and post-processing times. Recently, an end-to-end system for focus stacking has been proposed that automatically selects images to acquire. The system is adaptive to the scene being imaged and shows excellent performance on a mobile device, where the lens has a short focal length and fixed aperture, and few images need to be selected. However, with longer focal lengths, variable apertures, and more selected images (as exists with other cameras, notably DSLRs), classification and algorithmic inaccuracies become apparent. In this paper, we propose improvements to previous work that remove these limitations, and show on eight real scenes that overall our techniques lead to improved accuracy while reducing the number of required images.
Software and data
The C++ source code and related files: README.txt, Src_fs.zip.

Figure 1. (Top) Single image captured with a 50mm lens and an aperture of f/13. (Bottom) All-in-focus image constructed by fusing 11 images each captured with a 50mm lens and an aperture of f/8.
Project: White balancing algorithms
Citation
(PDF) Peter van Beek and R. Wayne Oldford. Illuminant estimation using ensembles of multivariate regression trees. Proceedings of IS&T Electronic Imaging: Computational Imaging XVI, Burlingame, California, February, 2018. An earlier version containing more detailed results can be found at: arXiv:1703.05354
Abstract
White balancing is a fundamental step in the image processing pipeline. The process involves estimating the chromaticity of the illuminant source and using the estimate to correct the image to remove any color cast. Given the importance of the problem, there has been much previous work on illuminant estimation. Previous work is either more accurate but slow and complex, or fast and simple but less accurate. In this paper, we propose a method for illuminant estimation that uses (i) fast features known to be predictive in illuminant estimation and (ii) single feature decision boundaries in ensembles of multivariate regression trees, (iii) each of which has been constructed to minimize a multivariate distance measure appropriate for illuminant estimation. The result is an illuminant estimation method that is simultaneously fast, simpler, and more accurate.
Software
The MATLAB source code and related files: README.txt, Src_wb.zip.
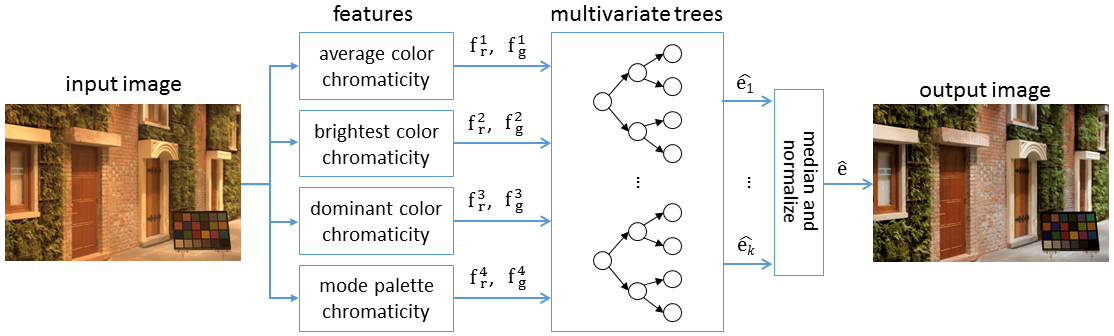
Figure 1. Our adaptation of Cheng et al.'s (CVPR 2015) learning-based method. Given an input image, four pairs of feature values are calculated, the feature values are used by each tree in the ensemble to predict the illumination, and the individual predictions are combined into a single estimate of the illuminant that is used to white balance the image.

Figure 2. An example multivariate regression tree when the distance measure is recovery angular error, showing only the first four layers (out of 18 layers). The three (green) leaf nodes are labeled with the number of training examples at that node and the illuminant estimation if that node is reached. Also shown are the four images associated with the bottom-most leaf node; the images have been gamma corrected for presentation.
Project: High dynamic range imaging
Paper
(PDF) Peter van Beek. Improved image selection for stack-based HDR imaging. Proceedings of IS&T Electronic Imaging: Photography, Mobile, and Immersive Imaging, Burlingame, California, January, 2019.
Abstract
Stack-based high dynamic range (HDR) imaging is a technique for achieving a larger dynamic range in an image by combining several low dynamic range images acquired at different exposures. Minimizing the set of images to combine, while ensuring that the resulting HDR image fully captures the scene's irradiance, is important to avoid long image acquisition and post-processing times. The problem of selecting the set of images has received much attention. However, existing methods either are not fully automatic, can be slow, or can fail to fully capture more challenging scenes. In this paper, we propose a fully automatic method for selecting the set of exposures to acquire that is both fast and more accurate. We show on an extensive set of benchmark scenes that our proposed method leads to improved HDR images as measured against ground truth using the mean squared error, a pixel-based metric, and a visible difference predictor and a quality score, both perception-based metrics.
Software
The MATLAB source code and related files: README.txt, Src_hdr.zip.

Figure 1. Pipeline for proposed end-to-end system for image set selection for construction of HDR image of a scene.