Note
This project list is no longer maintained; for current projects, please visit my UBC page.
Here is a collection of some of the projects I have been the primary investigator on during my research career. They are listed in approximately reverse-chronological order.Detecting unexpected behavioural changes
While developers often have a strong understanding of the static nature of their changes, the dynamic effects of these changes on the runtime behaviour of the program can be harder to comprehend. This approach automatically classifies the impact of a developer's change so they can better understand the dynamic consequences their modification tasks. The overall goal of this project is to enable developers to reason about the dynamic behaviour of their systems in a way that helps prevent unintended behavioural changes from being made.
We created a short video overview of our approach for a research demonstration at ICSE 2011:
CrystalVC: Proactive conflict detection
Crystal's goal is to increase developer awareness of conflicts. When two or more developers collaborate, it is possible for their independent changes to conflict — either syntactically as a version control conflict or behaviourally if the changes merge cleanly but have unintended interactions. The Crystal tool informs each developer of the answer to the question, “Might my changes conflict with others' changes?”
Crystal monitors multiple developers' repositories. It informs each developer when it is safe to push her changes, when she has fallen behind and could pull changes from others or a central repository, and when changes other developers have made will cause a syntactic or behavioural conflict.
If conflicts occur, Crystal informs developers early, so they may resolve these conflicts quickly. Long-established conflicts can be much harder to resolve. If changes are made without conflicts, Crystal gives developers confidence to merge their changes without fearing unanticipated side effects.
YooHoo: Customized change awareness
It is often assumed that developers' view of their system and its environment is always consistent with everyone else's; in practice, this assumption can be false, as the developer has little practical control over changes to the environments in which their code will be deployed. To proactively respond to such situations, developers must constantly monitor a flood of information involving changes to the deployment environments; unfortunately, the vast majority of this information is irrelevant to the individual developer, and its sheer volume makes it likely that infrequent change events of relevance to them will be lost in the noise. As a result, errors may arise at deployment time that the developer will not be aware of for an extended delay.
This project examines a recommendation approach for filtering the flood of change events on deployment dependencies to those that are most likely to cause problems for the individual developer. The approach is evaluated for its ability to drastically filter irrelevant details, while being unlikely to filter important ones. The relevance of the results is assessed on the basis of deployment problems that would have historically occurred within a set of industrial systems.
Gilligan: Pragmatic software reuse

Software reuse typically involves reusing components specifically designed for reuse; these components must provide the exact functionality that a developer requires and must fit within their system without structural or behavioural mismatch. When these two conditions are not met, developers have the opportunity to investigate pragmatic software reuse approaches; in these situations the software being reused may not have been designed specifically for reuse, but may enable the developer to greatly reduce the time and cost of developing similar software from scratch. In these cases developers must extract some portion of the source code, modify it to suit their needs, and integrate it into their own system.
To address shortcomings in performing these tasks manually, I created the Gilligan pragmatic-reuse environment [CV5, CV10, CV2, CV17]. Developers using my planning tool were able to locate twice as many relevant program elements compared to traditional approaches [CV10]; they needed to resolve 98% fewer compilation errors [CV2]; they were 32% more likely to successfully complete a pragmatic reuse task [CV17]; and they took significantly less time to perform their pragmatic reuse tasks [CV17].
Supporting end-to-end code search
Source code examples are valuable to developers needing to use an unfamiliar application programming interface (API). Numerous approaches exist to help developers locate source code examples; while some of these help the developer to select the most promising examples, none help the developer to reuse the example itself. Without explicit tool support for the complete end-to-end task, the developer can waste time and energy on examples that ultimately fail to be appropriate; as a result, the overhead required to reuse an example can restrict a developer's willingness to investigate multiple examples to find the "best" one for their situation. This paper outlines four case studies involving the end-to-end use of source code examples: we investigate the overhead and pitfalls involved in combining a few state-of-the-art techniques to support the end-to-end use of source code examples.
DeepIntellisense: Surfacing context-sensitive information in IDEs
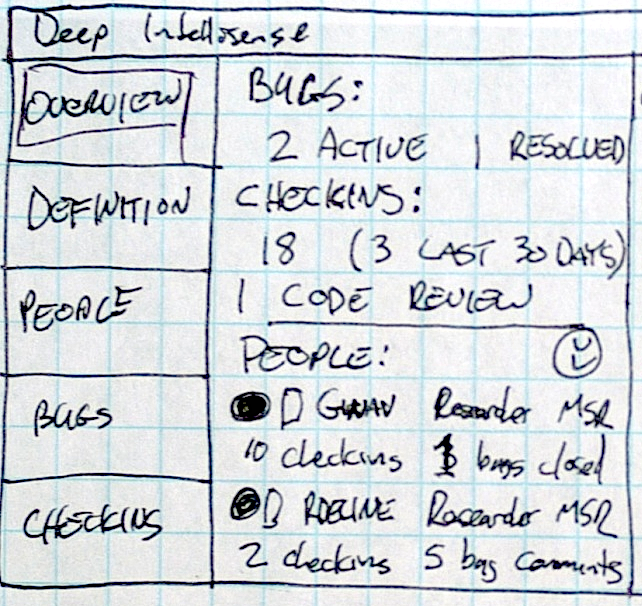
Software engineers working in large teams on large, long-lived code-bases have trouble understanding why the source code looks the way does. Often, they answer their questions by looking at past revisions of the source code, bug reports, code checkins, mailing list messages, and other documentation. This process of inquiry can be quite inefficient, especially when the answers they seek are located in isolated repositories accessed by multiple independent investigation tools. Prior mining approaches have focused on linking various data repositories together; in this paper we investigate techniques for displaying information extracted from the repositories in a way that helps developers to build a cohesive mental model of the rationale behind the code. After interviewing several developers and testers about how they investigate source code, we created a Visual Studio plugin called Deep Intellisense that summarizes and displays historical information about source code. We designed Deep Intellisense to address many of the hurdles engineers face with their current techniques, and help them spend less time gathering information and more time getting their work done.
PopCon: Identifying important API
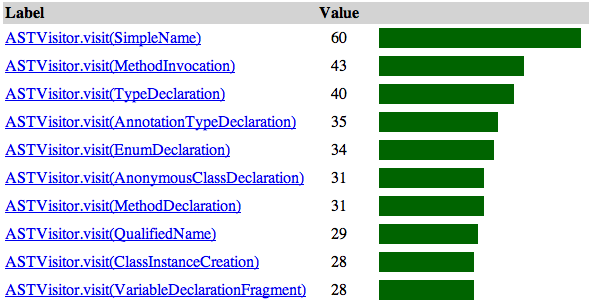
Eclipse has evolved from a fledgling Java IDE into a mature software ecosystem. One of the greatest benefits Eclipse provides developers is flexibility; however, this is not without cost. New Eclipse developers often find the framework to be large and confusing. Determining which parts of the framework they should be using can be a difficult task as Eclipse documentation tends to be either very high-level, focusing on the design of the framework, or low-level, focusing on specific APIs. We have developed a tool called PopCon that provides a bridge between high-level design documentation and low-level API documentation by statically analyzing a framework and several of its clients and providing a ranked list of the relative popularity of its APIs. We have applied PopCon to the Eclipse framework for this challenge to help newbie Eclipse developers identify some of the most relevant APIs for their tasks.
Strathcona: Context-sensitive example recommendation
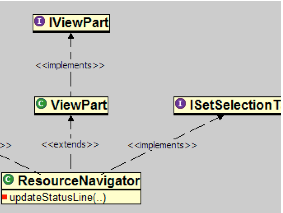
When coding to an application programming interface (API), developers often encounter difficulties, unsure of which class to subclass, which objects to instantiate, and which methods to call. Example source code that demonstrates the use of the API can help developers make progress on their task. This paper describes an approach to provide such examples in which the structure of the source code that the developer is writing is matched heuristically to a repository of source code that uses the API. The structural context needed to query the repository is extracted automatically from the code, freeing the developer from learning a query language or from writing their code in a particular style. The repository is generated automatically from existing applications, avoiding the need for handcrafted examples. We demonstrate that the approach is effective, efficient, and more reliable than traditional alternatives through four empirical studies.