As we have seen in the previous section,
if jobs do not execute with high average
efficiency,
the mean response times obtained
using scheduling algorithms that make allocation
decisions based only on ![]() are quite high when
compared with a scheduling algorithm that makes
no use of job characteristics.
This is because jobs are being allocated
processors that they are not able to use
effectively.
In this section, we consider
scheduling policies which only use
information about a job's efficiency.
are quite high when
compared with a scheduling algorithm that makes
no use of job characteristics.
This is because jobs are being allocated
processors that they are not able to use
effectively.
In this section, we consider
scheduling policies which only use
information about a job's efficiency.
Various policies are considered by using different
values of ![]() to allocate processing power
according to the efficiency with which a job
executes.
Positive values of
to allocate processing power
according to the efficiency with which a job
executes.
Positive values of ![]() will allocate more
processors to jobs with higher efficiency while
negative
will allocate more
processors to jobs with higher efficiency while
negative ![]() values allocate more processors
to jobs with low efficiency
(an obviously bad approach).
Since under our workload model the efficiency of
each job is characterized by
values allocate more processors
to jobs with low efficiency
(an obviously bad approach).
Since under our workload model the efficiency of
each job is characterized by ![]() ,
we set
,
we set ![]() and use:
and use:
![]()
The graph in Figure 5
plots the mean response time against
different ![]() values
(representing different scheduling policies)
and shows results for
values
(representing different scheduling policies)
and shows results for ![]() = 1 and 5.
(
= 1 and 5.
( ![]() yields such a pronounced
v-shape that it is not included because it
hides the distinction between
yields such a pronounced
v-shape that it is not included because it
hides the distinction between
![]() and
and ![]() .)
This graph shows that as
.)
This graph shows that as ![]() increases,
in both positive and negative directions,
the mean response time also increases.
These experiments were conducted using
increases,
in both positive and negative directions,
the mean response time also increases.
These experiments were conducted using
![]() and
and
![]() and a low target load (30%).
Even under this light load we find that with
and a low target load (30%).
Even under this light load we find that with
![]() performance degrades significantly
for
performance degrades significantly
for ![]() and
and ![]() .
We use this light load to demonstrate the
general shape of the response time curves since
at higher loads the differences in mean response
times for the various algorithms change drastically
(i.e., the v-shape becomes more
pronounced more quickly).
Under this scheme,
positive
.
We use this light load to demonstrate the
general shape of the response time curves since
at higher loads the differences in mean response
times for the various algorithms change drastically
(i.e., the v-shape becomes more
pronounced more quickly).
Under this scheme,
positive ![]() values imply that more processors
are given to jobs with higher efficiency.
Significantly increasing the number of
processors allocated to
efficient jobs,
while improving the degree to which processors
are efficiently utilized,
does not improve mean response time.
This is because jobs that might potentially take a
short amount of time to execute can become stuck
behind jobs that take a long time to execute.
values imply that more processors
are given to jobs with higher efficiency.
Significantly increasing the number of
processors allocated to
efficient jobs,
while improving the degree to which processors
are efficiently utilized,
does not improve mean response time.
This is because jobs that might potentially take a
short amount of time to execute can become stuck
behind jobs that take a long time to execute.
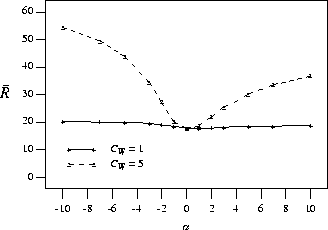
Figure 5: Mean response time versus scheduling policy ( ![]() );
); ![]()
Note that the mean response time
obtained when ![]() is relatively close to that
obtained when
is relatively close to that
obtained when ![]() .
In fact in most cases it yields mean response
times that are statistically equal to
those obtained with
.
In fact in most cases it yields mean response
times that are statistically equal to
those obtained with ![]() .
Because the
.
Because the ![]() and
and ![]() values
are so similar we now more closely
examine these algorithms and also consider another
point on the spectrum of algorithms (
values
are so similar we now more closely
examine these algorithms and also consider another
point on the spectrum of algorithms ( ![]() ).
).
Table 2 contains the mean response times and
90% confidence intervals for ![]() = 0, 0.5, and 1.0
for workloads with
= 0, 0.5, and 1.0
for workloads with ![]() = 1, 5, and 30 and
ranges of effective efficiency of
1-50%, 1-99%, and 50-99%.
The column labelled ``%Impr'' gives the
percent by which the mean response time of
= 1, 5, and 30 and
ranges of effective efficiency of
1-50%, 1-99%, and 50-99%.
The column labelled ``%Impr'' gives the
percent by which the mean response time of ![]() is reduced if
is reduced if ![]() is used.
(A negative value indicates the mean response time
has increased,
however, these negative differences
can not be considered to be
statistically significant.)
Each experiment was run using an arrival rate that
produces observed loads
of approximately 90%.
Interestingly, when average efficiency is
relatively low, the algorithm obtained when using
is used.
(A negative value indicates the mean response time
has increased,
however, these negative differences
can not be considered to be
statistically significant.)
Each experiment was run using an arrival rate that
produces observed loads
of approximately 90%.
Interestingly, when average efficiency is
relatively low, the algorithm obtained when using
![]() produces mean response times that
are lower than those obtained when
produces mean response times that
are lower than those obtained when
![]() or
or ![]() .
.
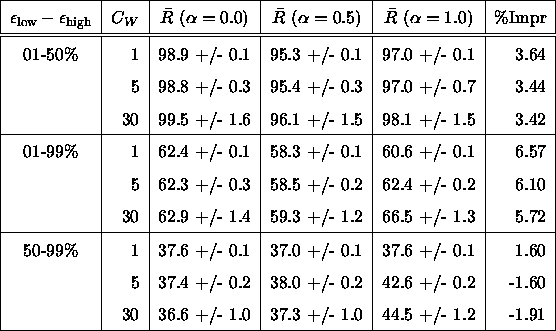
Table 2: Comparison of mean response times for different policies based on efficiency
We believe that with ![]() too many
processors are allocated to jobs that are not
capable of utilizing them effectively.
Because of the nature of how
too many
processors are allocated to jobs that are not
capable of utilizing them effectively.
Because of the nature of how
![]() determines the efficiency of each job
we expect that the improved mean response times obtained for
determines the efficiency of each job
we expect that the improved mean response times obtained for
![]() are more indicative of how to
schedule using
are more indicative of how to
schedule using ![]() than how to schedule
using other characteristics of a job's efficiency.
(For example, we expect that if
than how to schedule
using other characteristics of a job's efficiency.
(For example, we expect that if ![]() was
used
was
used ![]() might perform better than
might perform better than
![]() .)
However, these results do demonstrate that a
characteristic of each job's
efficiency,
.)
However, these results do demonstrate that a
characteristic of each job's
efficiency, ![]() in this case,
can be used to make processor allocation decisions
and produce
mean response times that are statistically lower
than an equipartition strategy.
However, these differences are quite small.
in this case,
can be used to make processor allocation decisions
and produce
mean response times that are statistically lower
than an equipartition strategy.
However, these differences are quite small.