Past Projects (Partial List)
 |
Afterburner: Interactive SQL analytics in your browser!Modern browsers embed JavaScript engines capable of powering real-time collaborative tools, driving online multi-player games, rendering impressive 3D scenes, and even running first-person shooters. Is it possible to exploit modern JavaScript engines and build a high-performance analytics database that runs completely in the browser? Afterburner is our answer. |
 |
Warcbase: A Web Archiving Platform Built on Modern "Big Data" InfrastructureThe goal of the Warcbase project is to build an open-source platform for storing, managing, and analyzing web archives using modern "big data" infrastructure specifically, HBase for storage and Hadoop for data analytics. Warcbase itself is available on GitHub. This project is supported by the Mellon Foundation, via Columbia University. |
 |
Providing Relevant and Timely Results: Real-Time Search Architectures and Relevance AlgorithmsWe aim to advance the state of the art in information retrieval by tackling real-time search, and more broadly, addressing retrieval challenges associated with streams of documents. See our project page for more details. |
 |
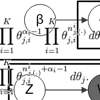
Learning to Efficiently Rank with CascadesWe have been developing a research program, dubbed "learning to efficiently rank", that allows algorithm designers to capture, model, and reason about tradeoffs between the effectiveness and efficiency of an information retrieval algorithm in a unified framework. See our project page for more details. |
 |
Cross-Language Bayesian Models for Web-Scale Text Analysis Using MapReduceWe are exploring highly-scalable MapReduce algorithms for linguistic modeling within a Bayesian framework, making use of variational inference to achieve a high degree of parallelization on web-scale datasets. See our project page for more details. As part of this project, we have developed Mr.LDA, an open-source toolkit for flexible, scalable, multilingual topic modeling using variational inference in MapReduce. |
 |
Ivory — A Hadoop Toolkit for Distributed Text RetrievalIvory is a Hadoop toolkit for distributed text retrieval that features a retrieval engine based on Markov Random Fields. The project is focused on the challenges of indexing and retrieval algorithms at web scale. See our project page for more details. |
 |
Statistical Machine Translation with MapReduceWe have been exploring the intersection of large-scale text retrieval and statistical machine translation. One thread has been scaling up iterative machine learning algorithms to larger and larger dataset. Another thread has been the application of IR techniques to automatically extract bilingual training data. See this project page for a completed project from the Google/IBM Academic Cloud Computing Initiative and NSF's CLuE program. |
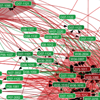 |
The iOpener project brings together bibliometrics, computational linguistics, and information visualization to generate readily-consumable surveys of different scientific domains and topics, targeted to different audiences and levels, e.g., expert specialists, scientists from related disciplines, educators, students, government decision makers, and citizens. |
 |
Crossbow is a Hadoop-based version of Bowtie, a short read aligner based on the Burrows-Wheeler Transform. It started off as a course project in my Spring 2009 cloud computing course. Representative publication:
|
 |
CloudBurst is a short read mapping algorithm for DNA sequence analysis implemented in MapReduce. It began as a course project in my cloud computing course in Spring 2008. Representative publication:
|
 |
The Clinical QA project leveraged a combination of knowledge-based and statistical text processing techniques to build systems that satisfied the information needs of physicians practicing evidence-based medicine. Representative publications: |
 |
The Computational Linguistics for Metadata Building (CLiMB) project produced a Cataloger’s Toolkit for enhancing subject access to digital image collections. The toolkit leverages computational linguistic techniques to mine scholarly texts for metadata terms. |