Sampling-based Predictive Database Buffer Management
Abstract
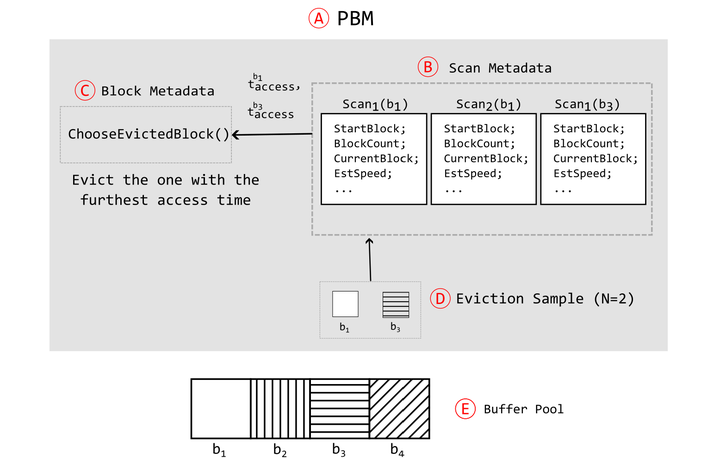
Systems often need to support analytical (OLAP) workloads that perform concurrent scans of data on secondary storage. The buffer manager is tasked with fetching data into the database system’s buffer pool and caching it there so as to increase the hit rate on these data, thereby lowering query latencies. This paper presents a database buffer caching policy that uses information about long-running scans to estimate future accesses. These estimates are used to approximate an optimal buffer caching policy that would otherwise infeasibly require knowledge about future accesses. Since a buffer caching policy must be efficient with low overhead, we present sampling-based predictive buffer management techniques where buffer eviction considers only a small random sample of buffers and access time estimates are used to select from the sample. This design is advantageous as it is easily tuned by adjusting the sample size, and easily modified to improve access time estimates and to expand the set of workload types that can be predicted effectively. We evaluate our techniques through both simulation studies on real Amazon Redshift workload traces and through implementation into the well-known open-source PostgreSQL database system with the popular TPC-H OLAP and YCSB benchmarks. We show that our approach delivers substantial performance improvement for workloads with scans, reducing I/O volume significantly including by up to 40% over PostgreSQL’s Clock-sweep policy and over prior predictive approaches for workloads using a mix of sequential scans and index accesses.