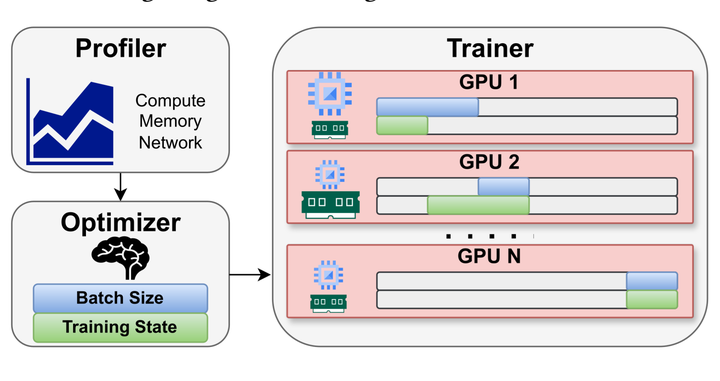
Abstract
Training transformer models requires substantial GPU compute and memory resources. While training systems are typically designed for homogeneous GPU clusters, sufficiently large homogeneous clusters are difficult to acquire for most organizations due to cost and GPU scarcity. Hence, it is increasingly common to assemble heterogeneous clusters with a mix of higher and lower-end GPUs featuring differing compute power and memory capacity. Existing methods attempt to distribute the workload across heterogeneous GPUs based on compute capacity but often underutilize compute due to memory constraints. We present Cephalo, a system that holistically balances both compute and memory usage by decoupling compute distribution from training state assignment. Cephalo uses an optimizer to efficiently distribute the compute workload and storage of training state to account for GPU heterogeneity in the cluster. Additionally, it separates memory from compute requirements through an optimized gradient accumulation strategy. Compared to state-of-the-art methods, Cephalo achieves 1.2×–10.8× higher training throughput while supporting larger models and batch sizes.