Relational Encodings
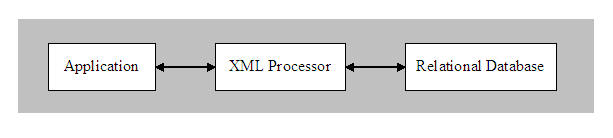
Storing XML in relational
databases
- Using LOBs
- Shredding (using example of Encyclopedia Britannica bibliography)
- schema-specific
- using “inlining”
to avoid “over-normalization”
| biblio (entry, position, paraID) | /* entry is a sequence of paragraphs */ |
| para (paraID, position, type, text, refID) | /* each position has a text or a ref (indicated by type) */ |
| ref (refID, position, type, text, citeID) | /* same for refs */ |
| cite (citeID, type, author, title, edition, date) |
- schema-independent
doc (docID, position, nodeID)
elements (nodeID, type, namespace, ...)
attributes (nodeID, attr, value)
children (nodeID, position, childNodeID)
- Interval-based representation
- Used
in conjunction with LOBs for content
node (type, start, end, level)
- need to support reconstruction
(“compose”), in particular save positional information
- combination of outer joins,
outer unions, sorting, and post-tagging
- need to map XML Schema types
to RDBMS datatypes
- Partial shredding
- Dynamic shredding
“Publishing”
relations as XML
- Transformation-based approach
- Default mapping using one of:
- <relation
name="R"> <tuple><attr
name="A1">vA11</attr><attr
name="A2">vA21</attr>...</tuple>
<tuple><attr name="A1">vA12</attr><attr
name="A2">vA22</attr>...</tuple> ...
</relation>
- <R><tuple><A1>vA11</A1><A2>vA21</A2>...</tuple>
<tuple><A1>vA12</A1><A2>vA22</A2>...</tuple>
... </R>
- <R><tuple
A1="vA11" A2="vA21".../> <tuple
A1="vA12" A2="vA22".../> ... </R>
- Transformations from the
default mapping (using XQuery or XSLT)
- Pull-based approach using “annotated” XML
schema
- for each element and
attribute, indicate which relation-attribute-value should be used to
populate the elements
- include constraints to ensure
that parent-child (and other) relationships are appropriately filled
Simultaneous use of SQL
and XQuery
- Introduce XML datatype to SQL
- need to choose a physical
representation (same choices as above)
- operators:
- XML to XML: query(XML,
XQueryString) -> XML
- XML to relational: value(XML,
XQueryString, SQLType) -> SQLType
- relational to XML: compose(SQLExpr)
-> XML
- Introduce table datatype to
XQuery
- need to choose a default
wrapping
- Incompatibilites
- Datatypes attached to
collections (columns) in SQL, but to individuals (elements) in XQuery
- Mismatch of datatypes and
operators on those types
- Collation sequences attached
statically to collections (columns) in SQL, but dynamic in XQuery
- Specification of schema
namespaces
- Space of legal names for
components
- Assumptions with respect to ordering
of components (influences on optimizations)
- Access to external,
user-provided parameters and correlation values
Waterloo’s Text ADT
extensions to SQL
- Algebraic operators
- Extraction: Table x Column x
TreePattern -> Table
- Element Construction: Table x Columns x Columns
x TagName-> Table
- Sorting: Table x Columns ->
Table
- Grouping: Table x Columns ->
GroupedTable
- Aggregate Construction: GroupedTable x TagName
-> Table
- Example
<biblio>
{
for $r in
doc(“eb-bib.xml”)//cite
where
$r/author
return
<citation>{$r}</citation>
}
</biblio>
Assume a table
documents (URI, content)
project( select(documents, URI=“eb-bib.xml”) , content)
-> R1(content)
extract( R1, content, “//cite#/author#”) ->
R2(content,cite,author)
project( select(R2, not null(author)), cite) -> R3(cite)
elem-constr( R3, {cite},{}, citation ) -> R4(cite,citation)
project( sort( R4, {cite}), citation) ->R5(citation) /* assumes doc-order */
agg-constr( group(R5,{}), biblio)
- New rewrite optimizations
- combine several extractions
into one
- eliminate redundant grouping
and construction operations
- pull up extractions to be
executed after selective joins
- push down extractions through
joins that result in duplicated text values
Mixed SQL/XQuery
processing in SilkRoute 2
- User view: XQuery evaluated on
XML
- Internally, two search engines:
SQL filter followed by XQuery evaluation on each tuple
- Supports spectrum from storing
XML as a whole to complete shredding
- Uses relations to index values
from within XML columns
Occursi(TupleIDi, Path, Data, Position)
- Performance improved by having
SQL filter as many tuples as possible before passing the resulting stream
to the client for final XQuery evaluation on each and final assembly of
result
- using the Occurs tables
- using LIKE to filter texts if
no OCCURS index is maintained
References and related
reading
Querying XML, Chapters 8, 15, B.4, C.3