Learning to Learn Group Alignment: A Self-Tuning Credo Framework with Multiagent Teams
David Radke* and Kyle Tilbury*
* denotes equal contribution
Proceedings: Adaptive and Learning Agents Workshop (ALA) at AAMAS 2023
[Click for Paper]
Abstract:
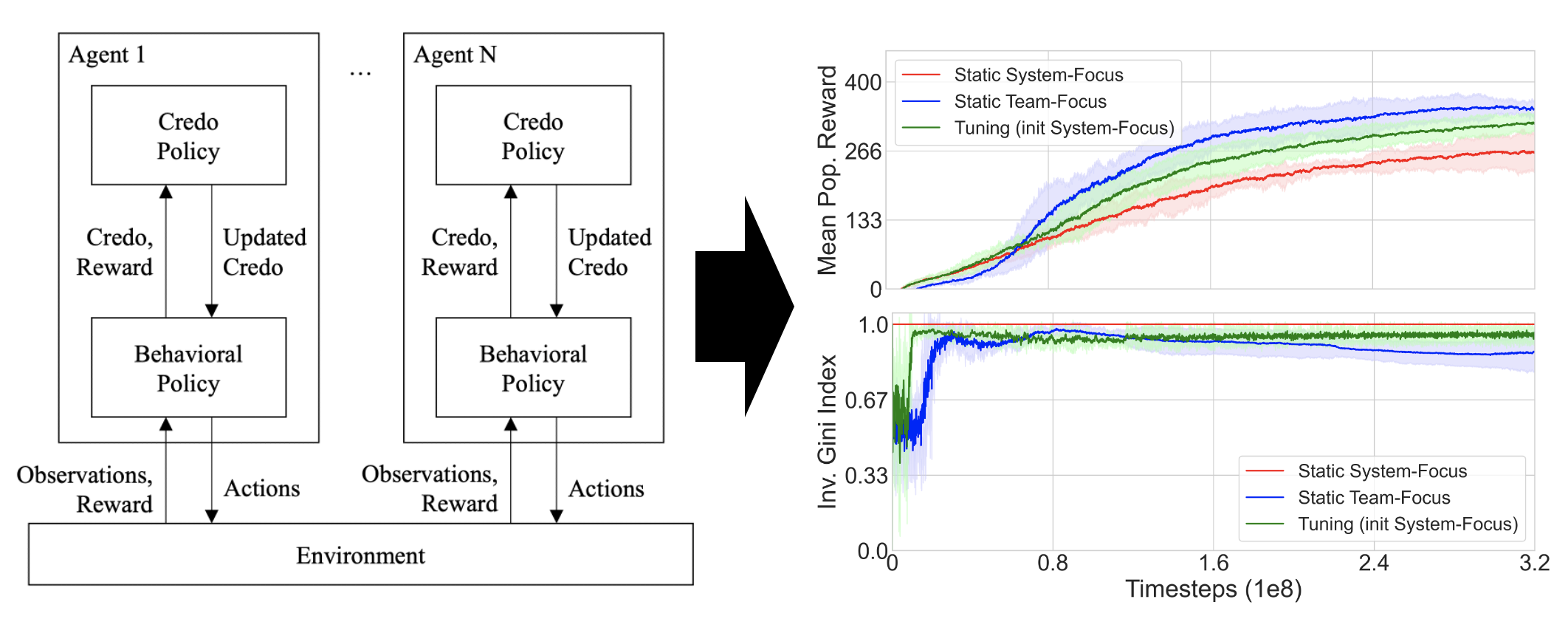
Mixed incentives among a population with multiagent teams has been shown to have advantages over a fully cooperative system; however, discovering the best mixture of incentives or team structure is a difficult and dynamic problem.
We propose a framework where individual learning agents self-regulate their configuration of incentives through various parts of their reward function.
This work extends previous work by giving agents the ability to dynamically update their group alignment during learning and by allowing teammates to have different group alignment.
Our model builds on ideas from hierarchical reinforcement learning and meta-learning to learn the configuration of a reward function that supports the development of a behavioral policy.
We provide preliminary results in a commonly studied multiagent environment and find that agents can achieve better global outcomes by self-tuning their respective group alignment parameters.