Louay Gammo, Tim Brecht, Amol Shukla, David Pariag,
Comparing and Evaluating epoll, select, and poll Event Mechanisms
6th Annual Ottawa Linux Symposium, Ottawa, Canada, July, 2004.
Preliminary Experiments with epoll on Linux 2.6.0
Tim Brecht, January 12 2004.
Note: these are very preliminary test results and they aren't testing the conditions that epoll was designed to run well under (i.e., environments where there are lots and lots of connections that may or may not be doing much).
We've been experimenting with using epoll_create, epoll_ctl, and epoll_wait in our user-level micro web-server call the userver
I've conducted a series of experiments comparing the performance of the userver using select, poll, and epoll. This set of experiments is very preliminary as we are still working on improving the epoll version. Note that we are currently only using level-triggered events. This is simply because select and poll are level-triggered and it made integration with the existing code easy (we hope to examine an edge-triggered approach in the future). This is a description of what we've been trying and finding so far.
The workload consists of 8 clients running httperf and pounding on the server by repeatedly requesting the same one file (sized to fit in one packet). There are no dead connections.
The server contains two 2.4 GHz Xeon processors. 1 GB of memory, and a fast SCSI disk. It has two on board Intel Pro/1000 NICs. It also contains two dual ported Intel MT Pro/1000 cards. The 8 clients are all dual Intel Xeon systems with IDE drives and 1 GB of memory. Each client has two on board Intel Pro/1000 ports/cards and a single dual ported Intel MT Pro/1000 card.
What each line in the experiment represents is explained below. The current again very preliminary results show that using the current implemenations (again we believe they can be improved more) for epoll, that select and poll perform better.
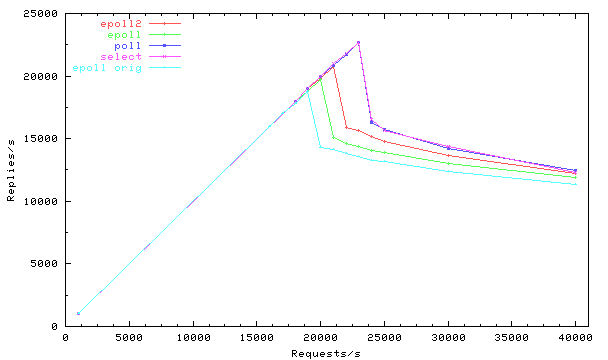
Experiments were conducted using the userver version 0.4.2 with the following options.
(epoll2) -c 15000 -f 32000 -C --use-sendfile --use-tcp-cork -m 0 --stats-interval 5 --use-epoll2 (epoll) -c 15000 -f 32000 -C --use-sendfile --use-tcp-cork -m 0 --stats-interval 5 --use-epoll (poll) -c 15000 -f 32000 -C --use-sendfile --use-tcp-cork -m 0 --stats-interval 5 --use-poll (select) -c 15000 -f 32000 -C --use-sendfile --use-tcp-cork -m 0 --stats-interval 5 (epoll orig) same as (epoll) above but code no longer exists as it was clearly a poor implementation.
- select -- uses select with multiple accepts. That is, when select indicates that the listening socket has something to read we repeatedly call accept to accept all outstanding connection requests. In otherwords we drain the accept queue. This is done in all cases for all servers. Note that it is possible that this may be accepting connections too aggressively in some cases (e.g., epoll2)?
- poll -- uses poll with multiple accepts.
-
epoll orig -- made too much use of epoll_ctl and did
so naively.
This was an artifact of starting from select based code
where we could cheaply and easily change the interest set.
(i.e., the list of sds (socket descriptors) we want to get events for).
Note: I usually distinguish file descriptors (fds) from socket descriptors
because as much as people would like you to believe that they
are the same the simple fact is that they aren't.
The problem with this version of the server is that a separate call
would be used to do something like:
/* now that we have the request we don't want info about * reading this sd but about writing this sd. */ interest_set_readble(sd); interest_set_writable(sd);The result was an excessive number of calls to epoll_ctl. -
epoll -- recognizing the excessive use of epoll_ctl above
this version improves the situation by using something like
the code below:
/* now that we have the request we don't want info about * reading this sd but about writing this sd. */ interest_set_change(sd, ISET_NOT_READABLE | ISET_WRITABLE);This type of improvement reduces the number of epoll_ctl calls by half. As can be seen by comparing epoll-orig and epoll this does help performance some. -
epoll2 -- in order to further reduce the number of calls to epoll_ctl
this version only does two epoll_ctl calls per connection.
The first to indicate that we have a new connection so we want
read and write events on that connection (sd).
The second occurs when we are done with the connection so we
need to tell epoll that we no longer want events for that connection (sd).
The problem with this approach is that because we are using level-triggered
operation we'll get events from epoll_wait that we don't have any
interest in.
For example, immediately after accepting a new connection we
want to read the incoming request.
Unfortunately using this option we'll get events that tell
us that we can write to the socket.
This is an event that we currently have no interest in
and the wait to avoid it is to use epoll_ctl to tell epoll
that we aren't interested -- but that's a system call and
it's expensive as you can see by comparing the performance
of epoll and epoll2.
-
So the pros and cons of this approach are:
- Con: We get extra events we don't care about from epoll_wait, this results in extra events copied from epoll_wait, and extra code being executed to check if we are interested in the event. For example, we only execute code to write responses if epoll_wait indicates that we can write without blocking and the finite state machine for the connection is in the FSM_WRITING_REPLY state.
- Con: epoll_wait returns sooner possibly with events we have no interest in. For example, if we are only interested in reading requests on all connections, we'll get events telling us that we can write to any of those connections. I expect that on average we'll get less useful work to do from oeach epoll_wait call and may end up doing epoll_wait calls more frequently as a result but I haven't confirmed/checked the numbers on this.
- Pro: We reduce the number of epoll_ctl calls.
- Pro: This seems to perform better under this workload than the epoll approach described above.
Some gprof Output
All output here is obtained using a separate run from the experiments shown in the graph above. We ran each experiment for one data point (i.e., a target request rate of 24000 requests per second). I've included any routines that account for 1% or more of the cpu time.Grof output using epoll (reply rate = 12523)
This version spends a significant portion of it's time in epoll_ctl (16.74%). This is used when a connection transitions for example from a state where it is reading a request to a state where it is writing a request. We tell the OS that we only want to know about events that permit us to write on that connection and we don't want to know about events that permit us to read on that connection (at this time). Comparatively there isn't that much time spent in epoll_wait (7.75%).
In all cases below we are using write to send the reply header, sendfile to send the file, and setsockopt to cork and uncork the socket so that the header and file can be sent in the same packet. The syscall to fcntl is used to place new sockets into non blocking mode.
Flat profile: Each sample counts as 0.000999001 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 20.12 22.58 22.58 read 16.74 41.37 18.79 7353337 0.00 0.00 sys_epoll_ctl 14.33 57.45 16.08 close 9.65 68.27 10.83 accept 9.27 78.67 10.40 setsockopt 7.75 87.37 8.69 20526 0.00 0.00 sys_epoll_wait 5.01 92.99 5.62 write 3.47 96.89 3.90 do_fcntl 2.74 99.96 3.08 sendfile 2.42 102.67 2.71 1673500 0.00 0.00 parse_bytes ----------------------------------------------------------------------
Grof output using epoll2 (reply rate = 12842)
This version is designed to reduce the amount of time spend doing epoll_ctl calls. This is achieved but at the expense of increasing the amount of time spent doing epoll_wait calls.
When compared with the technique above the number of epoll_ctl calls is reduced from about 7.3 million to about 4.1 million and the resulting portion of time spent in epoll_ctl is reduced from 16.74% to 10.49%. Interestingly the number of calls to epoll_wait has increased by two orders of magnitude. This is because (as noted in the description of the different methods above) we get a large number of events that we have no interest in. E.g., that we are able to write to a connection that we are currently trying to read from. Additionally, because there will almost always be events that are ready at the time of the call we get smaller numbers of events back on average (15.4 events per epoll_wait call). This compares with an average of 261.8 events from each epoll_wait call for the simple epoll version.
In this case we also see a bit of overhead from determining what state of the finite state machine we are in (get_fsm_state). This is required in this server because now we can get events from epoll_wait that we may not want to act on because we aren't in a state that warrants it. E.g., if the state we are in is reading a request we don't act on events that permit us to write to that connection (until we have the full request, have parsed it, etc.).
Flat profile: Each sample counts as 0.000999001 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 18.37 22.73 22.73 read 14.64 40.85 18.12 close 13.97 58.12 17.28 2779336 0.00 0.00 sys_epoll_wait 10.49 71.11 12.98 4144242 0.00 0.00 sys_epoll_ctl 8.99 82.23 11.12 accept 7.77 91.84 9.61 setsockopt 4.23 97.07 5.23 write 3.44 101.33 4.26 do_fcntl 3.14 105.22 3.89 sendfile 2.68 108.54 3.32 1745477 0.00 0.00 parse_bytes 1.88 110.86 2.32 85789176 0.00 0.00 get_fsm_state 1.76 113.04 2.18 42894588 0.00 0.00 do_epoll_event 1.27 114.61 1.58 gettimeofday ----------------------------------------------------------------------
Grof output using select (reply rate = 14196)
In this case we are using select and all control of which descriptors/events we are interested in are controlled by setting and/or clearing bits in the user address space. On the call to select that information is copied to and from the kernel. But because it doesn't require an extra system call per change in state for each connection there is not overhead for it and the select server is able to perform considerably better (** under this workload **).
Flat profile: Each sample counts as 0.000999001 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 19.71 21.99 21.99 read 15.87 39.70 17.71 close 14.31 55.66 15.96 select 11.73 68.74 13.08 setsockopt 10.21 80.13 11.39 accept 6.27 87.13 7.00 write 4.01 91.60 4.47 do_fcntl 3.74 95.77 4.17 sendfile 2.59 98.66 2.89 1916279 0.00 0.00 parse_bytes 1.31 100.12 1.46 25416050 0.00 0.00 check_and_do_read_write 1.23 101.50 1.38 32857 0.00 0.00 process_sds 1.13 102.77 1.26 4133040 0.00 0.00 socket_readable ----------------------------------------------------------------------
Grof output using poll (reply rate 14471). Note that in this instance poll is slighly better than select. In this case get_fsm_state appears because on 2.6.0 I noticed instances (potential bugs I think) where poll would report that socket writable event even when that event was not in the interest set. The work around for this test was to add code to check the connections state (in the finite state machine) before doing reads and/or writes. Otherwise we were trying to write when we shouldn't have been.
Flat profile: Each sample counts as 0.000999001 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 18.71 19.76 19.76 read 15.93 36.57 16.81 close 14.06 51.40 14.84 poll 11.32 63.36 11.95 setsockopt 10.33 74.26 10.91 accept 5.93 80.52 6.26 write 3.93 84.66 4.15 do_fcntl 3.86 88.74 4.08 sendfile 2.62 91.50 2.76 1768890 0.00 0.00 parse_bytes 1.00 92.56 1.05 5657788 0.00 0.00 get_fsm_state ----------------------------------------------------------------------
Future work
-
Try to further improve epoll performance.
- Look at doing an edge-triggered implementation.
- One thought here is that we may want something like an epoll_ctlv call that allows us to change interest in a bunch of different connections with one call, rather than one system call per change as is currently required. We'll confirm that the overhead incurred by epoll_ctl is still significant before exploring this.
- In the epoll2 version, epoll_wait is returning without very many events of interest. One possibility might be to have epoll_wait wait until there are more events of interest. Some interfaces permit one to specify a minimum number of events to wait for but I'm not sure how one picks that minimum number properly in all circumstances.
- Examing balance/scheduling issues for epoll and epoll2. In the epoll2 case if epoll_wait is returning events quickly and the set of events contains a bunch of things we have no interest in (e.g., we can write on connections we are waiting to read from) then we may be more aggressively accepting connections than in other cases. So we may want to explore other --accept-count values besides (0 = infinity).
-
Looking at other workloads.
- SPECweb99-like workloads should require fewer epoll_ctl calls because of persistent connections.
- Look at WAN-like workloads. Perhaps by creating dead connections. The problem is that I fundamentally don't believe in the dead connections approach to simulating WAN environments. I suspect that most servers will simply timeout dead connections if they've been idle for too long.
Last modified: Mon Jan 12 11:36:47 EST 2004