What Type of Consistency Does Nessie Provide?
Nessie provides serializable consistency guarantees.
What Types of Workloads Are Most Suitable for Nessie?
Nessie yields especially high performance for the following types of workloads:
- Read-mostly workloads: Workloads that are read-mostly exhibit good performance characteristics for Nessie. In the best case, it is possible for a Nessie GET operation to complete using a single 64-byte RDMA read operation over the network, regardless of the data size.
- Workloads with high degrees of data-access locality: Nessie stores indexing metadata separately from key-value store data. This allows Nessie to exploit data locality. Workloads that take advantage of data locality incur minimal networking overhead, and complete very quickly.
- Workloads with skewed popularity distributions: Nessie implements a local cache that can optionally store frequently-accessed remote data. Workloads that frequently access a small number of very popular items benefit immensely from this cache, and can complete much more quickly. This type of workload is extremely common among applications, with many video, music, image and file sharing websites and applications exhibiting Zipfian traffic patterns.
- Workloads with large key-value pairs: The benefits obtained from Nessie's good use of locality and data placement increase as data sizes get larger. Nessie is well-suited towards workloads with large data items, even when those workloads are comprised manly of write operations.
- Workloads where CPU and energy consumption on "server" nodes matter: Nessie's client-driven consumes minimal CPU and energy on nodes that are only performing storage. Only clients consume these resources, and even then only when they are actively issuing a request.
- Workloads which require large degrees of scalability: Nessie's design allows it to seamlessly scale up to thousands of nodes. Nessie can additionally scale within a single physical node in order to take advantage of multiple NICs and other resources.
- Workloads where key space partitioning is difficult: Because Nessie does not require a pre-partitioning of the key space, workloads that would otherwise require a good partitioning to perform well may simply run without dealing with the complexities of creating the pre-partitioning.
What Techniques and Data Structures Does Nessie Employ?
To achieve good performance for the described use-cases (and others), Nessie relies primarily on the following techniques and data structures:
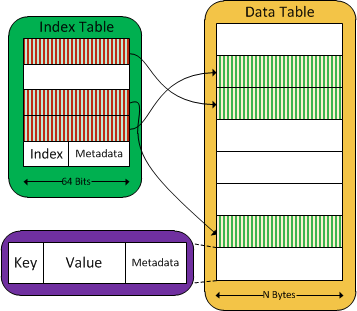
- Key-value pairs are stored in an RDMA-registered region on Nessie nodes. These regions are referred to as data tables.
- Information about which data tables contain which key-value pairs are stored in deterministically-computed indices inside separate RDMA-registered regions on Nessie nodes. These regions are referred to as index tables.
- Several possible index table entries exist for each key at deterministic locations. At a high level, the behaviour of the index tables is analogous to cuckoo hashing in a hash table.
- GET operations use RDMA reads to iterate over a key's potential index table entries and the data table entries to which they refer until the key-value pair is found.
- Like GETs, PUT and DELETE operations iterate over index table entries until an unused index is found, or an index referring to a previous value for the same key is found. This index is then updated using an atomic RDMA compare and swap (CAS) operation. Additional checks are put in place to guarantee that other operations cannot interfere with in-progress operations.
- Data table entries that reside on the node performing an operation are accessed locally through direct memory reads. This avoids congesting the NIC and provides higher performance. To guarantee that operations do not interfere with each other, 64-byte indexing metadata is always accessed through RDMA.
- Operations that retrieve key-value pairs from other nodes may optionally store these key-value pairs inside a local LRU cache, using the index table entry as the storage key. Future operations may then simply retrieve the key-value pair locally, provided it is still in the cache and has not expired.
- Index table entries contain bits from the hashes of the keys they refer to. These bits, referred to as filter bits, allow certain data table reads to be skipped during operations, as it can be immediately inferred from the filter bits in an index table entry that the data table entry it refers to does not match a particular key.
A simplified view of the storage architecture of a single Nessie node resembles the following:
Further Reading
For more in-depth information about the Nessie architecture, please see the documents available on the publications page.